Writing Release Notes When AI Agents Generate the Code


If you pushed a major feature to production five years ago, you could probably explain every line of it. You knew why you chose a specific database index, why you handled that weird edge case in the payment flow, and what other parts of the system might break if someone looked at them wrong.
When it came time to write the release notes, the problem wasn't figuring out what happened. The problem was remembering to write it down.
Now, your team is using coding agents. You describe the feature, the agent generates the code, the tests pass, and you merge it. It is fast. It is efficient.
And it leaves you with a profound documentation gap.
The code works, but the person publishing the release does not have the intimate knowledge they would if they had written it themselves. The commit messages are often generic. The pull request descriptions might be thin. Yet, your customers still need clear, accurate release notes that explain what changed, what is new, and what might break.
The challenge is no longer just writing down what you know. It is reconstructing intent from an artifact you only curated.
The Part Where the AI Forgets to Tell You What It Did
AI agents excel at implementation. They do not naturally produce the narrative layer humans need.
When a human writes a shortcut, they usually know it is a shortcut. They can explain why they did it. The debt is visible, at least to the person who created it.
When an AI generates code, the shortcuts are invisible. The developer who merged it may not even recognize them as shortcuts. They look like clean, well-structured code. They pass every check.
This creates a new kind of technical debt: comprehension debt. The code runs correctly, but nobody on your team can actually explain it. When a senior developer leaves and takes institutional knowledge with them, the loss is painful. With AI-generated code, the institutional knowledge was never there in the first place.

This gap becomes glaringly obvious when it is time to communicate changes to users. 1.7% of AI-generated pull requests exhibit high message-code inconsistency, where the description diverges significantly from the underlying code changes. The most common issue is "phantom changes," where the description claims unimplemented features.
If you rely solely on the agent's PR description to draft your release notes, you might be promising features that do not exist. Or missing critical behavioral shifts that do.
There is also a macro-level signal worth noting. Agents generate stronger commit-level messages but lag humans at PR-level summarization. Agents are good at narrating individual commits. They are less reliable at synthesizing the full story of what changed across a release. That synthesis is exactly what a release note requires.
Higher AI adoption is associated with an increase in both software delivery throughput and software delivery instability. More code, faster. More changes, less understood. The documentation gap is not a side effect. It is a structural feature of how AI agents work.
How to Find the Intent in the Artifacts
So, how do you write release notes when you didn't write the code? You have to mine the artifacts that still exist.
Even when an AI writes the code, there are inputs and outputs you can analyze to reconstruct the "why" behind the "what."
Start with the original prompt or task description. What was the developer trying to achieve? This is often the clearest statement of user-facing impact. A well-written prompt is, in effect, a pre-release note. It describes the problem being solved, the expected behavior, and the constraints. If your team is not saving these prompts, that is the first process change to make.
Next, examine the diff itself. While you might not know why the agent chose a specific implementation, you can see what files changed. Did it touch the database schema? Did it modify an API endpoint? Did it add or remove configuration options? The diff tells you what changed. Your job is to translate that into why it matters for the user.
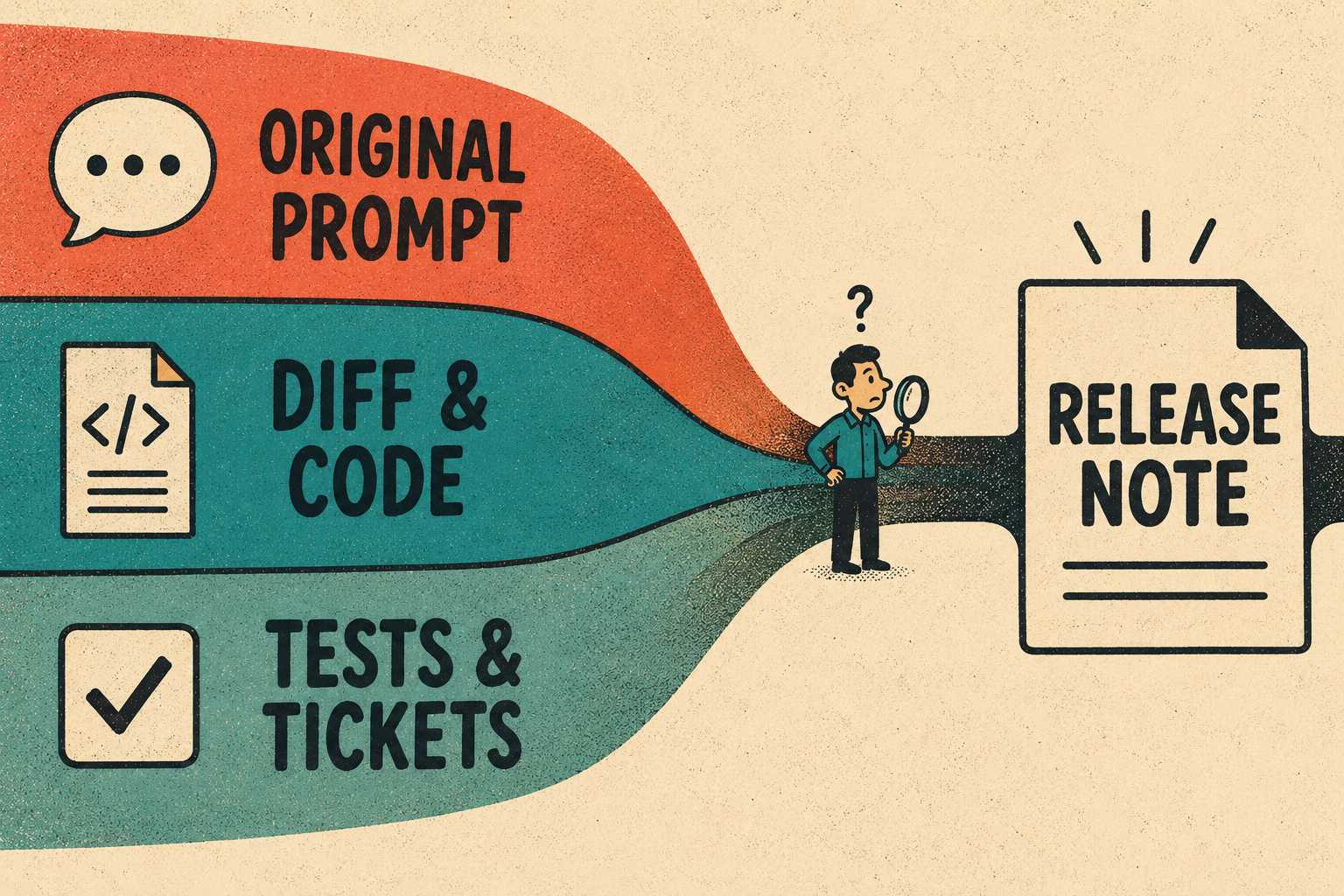
Test coverage is underused as a documentation source. Tests are executable specifications. What new behaviors are being tested? What edge cases did the agent anticipate? A new test for a null-pointer edge case in the payment flow tells you something important about what the agent decided to handle. That is worth surfacing in a release note.
Finally, look at related tickets, user requests, and any conversation history with the agent. The back-and-forth between the developer and the AI often reveals the constraints and tradeoffs that shaped the final code. If the developer asked the agent to "handle the case where the user has no billing address," that constraint is user-facing information. It belongs in the release notes.
The Checklist for Validating What the AI Actually Built
Before you publish a release note, you need to validate that the implementation matches the narrative.
This requires a structured approach to review. You cannot just accept the agent's summary at face value. The phantom changes problem is real, and it compounds at scale. Agent-authored pull requests are accepted less frequently than human ones, revealing a trust and utility gap that is partly a documentation problem.
Ask yourself these questions before publishing:
- Does the implementation match the original request?
- Are there edge cases the agent handled that were not in the spec?
- Did the agent make architectural decisions that affect other parts of the system?
- What assumptions did it encode that a human would have surfaced in review?
The last question is the hardest. AI agents do not flag assumptions. They encode them silently. A human developer who decides to cache a database query will usually mention it in the PR. An AI agent might do the same thing without any narrative explanation. If that cache has a TTL that affects data freshness, your users need to know.
This validation step is critical. As AI contributes more code, the documentation workflow has to shift earlier. You cannot rely on the developer's working memory anymore, because the developer's working memory is just a prompt history.
What a Good Release Note Actually Looks Like
A good release note in this context looks a lot like a good release note from five years ago. It just requires more discipline to produce.
Start with the user-facing impact. Explain what changed at a level appropriate for the audience. Flag breaking changes or behavioral shifts. Link to relevant documentation.
Consider a feature where an AI agent updated a reporting dashboard.
Weak (Relying on the agent's PR summary):
"Updated the reporting module. Refactored the SQL queries for better performance. Added new test coverage."
This tells the user nothing about why they should care. It is a list of technical chores.
Strong (Reconstructed intent):
"The weekly analytics dashboard now loads significantly faster, especially for accounts with high transaction volumes. We optimized the underlying data retrieval process to prevent timeouts during peak hours. Note: The 'Export to CSV' button has moved to the top right corner of the report view."
The strong version translates the technical implementation (refactored SQL) into user value (faster loading, no timeouts). It also highlights a behavioral shift (moved button) that the agent might have done incidentally, without any explicit instruction to do so.
That last part matters. AI agents make incidental decisions all the time. They reorganize UI elements, change default values, and alter error messages because the patterns in their training data suggest it is the right thing to do. None of that gets flagged as a "breaking change" in a commit message. It just ships. Your release notes are the last line of defense for catching it.
The Operational Reality of Scaling AI
As AI agents write more of your code, your process has to change.
Better prompts up front are not just good engineering hygiene. They are a documentation investment. A prompt that specifies the user-facing behavior, the edge cases, and the constraints is a pre-release note. Treat it that way. Save it. Version it. Link to it from the PR.
Structured commit messages help too, but they require discipline. Automated release note tools frequently fail when commit messages are inconsistent or non-compliant with conventions. If your team is using AI agents to generate commit messages, add a step to validate that the message accurately reflects the code change before merging.
Post-deployment validation is the step most teams skip. After a release, compare the release notes to the actual behavior in production. Did the feature work as described? Did the behavioral shifts you flagged actually occur? This feedback loop is how you calibrate the process over time.
The underlying shift is this: when humans write code, the documentation workflow can happen after the fact, because the developer carries the context in their head. When AI agents write code, the context has to be captured at the moment of generation. It does not persist anywhere else.
Doc Holiday generates structured release notes directly from repository activity, surfacing changes that might otherwise go undocumented when AI agents are involved. It takes the output from your engineering workflows, gives your team the structure to validate it, and scales the documentation process as AI contributes more to the codebase. Nothing ships without a clear explanation of what changed and why.


