What a Production-Grade OpenAPI Workflow Actually Looks Like


If you look at the support queues of any developer-first product, you'll find a quiet tragedy playing out daily. A customer will paste a curl command that perfectly matches the official documentation, and the support engineer will have to explain that actually, the API hasn't worked that way since last Tuesday.
The documentation is lying. And everyone involved knows it.

In theory, this shouldn't happen. The OpenAPI Specification is a machine-readable contract. If the code changes, the spec changes, and the reference documentation should write itself. In practice, most teams end up choosing between two bad options: hand-written docs that drift out of sync with the codebase, or auto-generation tools that produce skeletal output nobody wants to read. Empirical research on API documentation has consistently shown that poor documentation leads to developer frustration, wasted time, and API abandonment.
A production-grade OpenAPI-to-docs workflow doesn't have to be a choice between accuracy and readability. Here is what one actually looks like.
The Spec Quality Problem Nobody Talks About
Auto-generated documentation is only as good as the source spec.
If your generated docs are skeletal and confusing, the bottleneck usually isn't the generator. It's that the spec was written for contract validation, not for human communication. Engineers writing OpenAPI specs are thinking about type safety and schema correctness. They are not thinking about the developer who will read the output at 11pm trying to figure out why their webhook payload isn't matching what the docs describe.
A documentable spec requires meaningful descriptions in every field. It needs request and response examples that reflect real use cases, not placeholder strings like "string" or "example_value". Error schemas must match production behavior. Security requirements must be explicit. As Twilio's engineering team has noted, treating the spec as an additional source file that is updated alongside the rest of the project can work well for disciplined teams with robust testing strategies, but other teams find it a struggle to keep the spec synchronized with the service it describes.
This is why companies like Stripe run rigorous API review processes before any public-facing changes are released. Their governance team, staffed with engineers from across the organization, reviews every proposal with a public-facing impact. The spec quality matters more than the tooling. You cannot generate good documentation from a thin spec any more than you can bake a good loaf from bad flour.
The practical implication: before touching a documentation generator, audit the spec itself. Every endpoint should have a description that explains the business purpose, not just the HTTP method. Every parameter should have an example that reflects a real value a customer would actually send. Every error response should be documented with the conditions that produce it.
What Surrounds the Generator
Generation is the easy part. You feed a YAML file into a tool, and a webpage comes out.
The hard part is the layer around it.
A production workflow requires versioning, change detection, breaking change warnings, and deprecation notices. It needs interactive examples that actually work. It needs a way to catch regressions before they ship.
There are plenty of tools that handle parts of this well. Redoc offers a clean, Stripe-like three-panel experience. ReadMe provides developer hubs with guides, recipes, and feedback loops. Bump.sh focuses on Git and CI integration, automatic changelogs, and breaking change detection in pull requests. Swagger UI remains the reliable default for teams that need something running quickly.
But these tools share a common limitation: they document endpoints, not workflows. They list parameters exhaustively. They don't explain which parameters actually matter for common use cases. They don't tell a developer which three endpoints to call in sequence to accomplish the task they're actually trying to do.
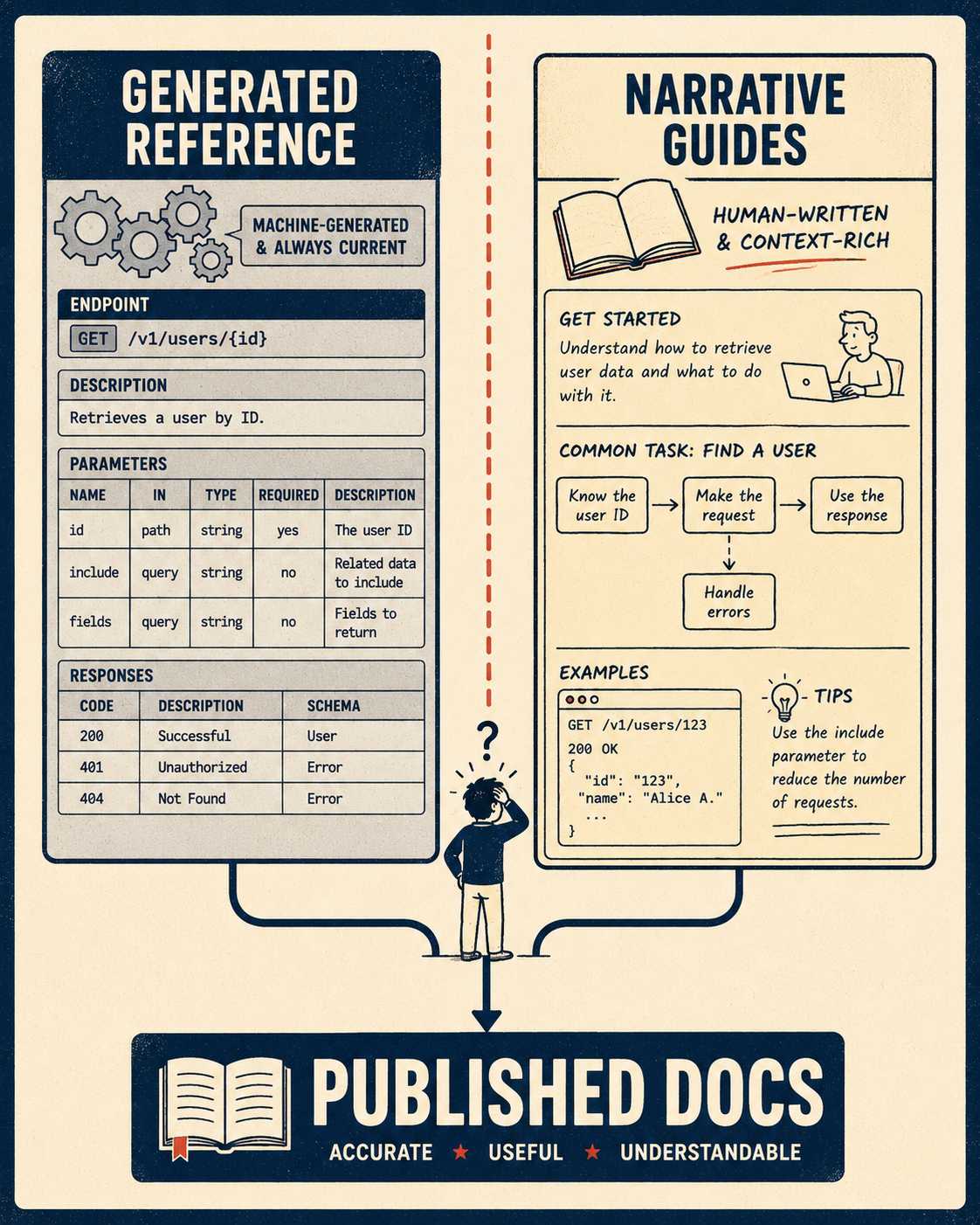
Research from SIGDOC found that developers approach documentation with a specific task in mind, not a desire to learn the API as a whole. They look for entry points. They want code examples they can copy and modify. They want to understand how concepts map to specific API elements. Auto-generated reference docs, however accurate, rarely provide this. The best documentation combines generated reference material with hand-written guides that show developers how to string endpoints together to solve actual problems. Mintlify's analysis of high-performing developer portals makes this explicit: auto-generated reference docs are a starting point, not a complete documentation strategy.
This hybrid model requires discipline. Generated references live in one section. Narrative guides live in another. The two are explicitly separated so readers always know whether they are looking at the machine truth or human interpretation of it.
Treating Documentation Like Code
Specs change constantly. A production workflow needs to catch regressions before they ship, and it needs to enforce quality standards automatically rather than relying on human reviewers to notice every missing field.
The answer is to treat documentation like code.
That means CI checks and linting rules. Tools like Spectral can enforce OpenAPI style guides and catch missing descriptions or inconsistent naming conventions during the build process. Tools like Detecting Breaking Changes in OpenAPI Specifications can detect breaking changes in pull requests before they are merged, flagging removals of required fields or changes to response schemas that would break existing integrations. When these checks are integrated into the CI/CD pipeline, documentation quality becomes enforceable. The pipeline fails the build if the spec isn't up to standard.
Stripe's versioning infrastructure is the most cited example of this done well. Their API changelog is programmatically generated and receives updates as soon as services are deployed with a new version. Their API reference documentation is tailored to individual users, annotating fields based on the user's pinned API version to warn them about backwards-incompatible changes since their integration was built. The documentation doesn't just describe the current state of the API; it describes the state of the API as the customer experiences it. That's a different problem, and it requires treating documentation as a first-class engineering artifact rather than an afterthought.
The practical checklist for a validation layer looks like this:
- Linting rules that fail the build on missing descriptions, missing examples, or inconsistent naming
- Breaking change detection on every pull request that modifies the spec
- Automated changelog generation tied to spec diffs
- Staging environment where generated docs are reviewed before going live
None of this is exotic. It's the same discipline applied to code quality, applied to documentation.
Where LLMs Change the Math
The introduction of LLM tooling on top of spec-based generation shifts the workflow in a meaningful way.
Modern tools can take a raw OpenAPI spec and produce narrative descriptions, usage examples, and conceptual context. They don't just output skeletal parameter tables. Recent research on LLM-based spec generation demonstrates that LLMs can understand the syntax and semantics of API implementations well enough to infer endpoint behavior, request structures, and response schemas without executing the code, achieving F1-scores above 97% for request parameter and response inference in controlled evaluations.
The workflow shifts accordingly. The spec feeds the generator. The generator produces structured output. The LLM layer enhances descriptions and adds context. Then, a human reviewer validates the accuracy and completeness before publication.
This is faster than manual writing and significantly more complete than bare auto-generation. The key word is "managed." AI generates at speed and scale. A reviewer with API design knowledge catches the errors, corrects the hallucinations, and validates that the output reflects actual production behavior before it reaches customers. The pipeline doesn't replace the reviewer; it makes the reviewer's time go further.
The Structural Advantage
When the source of truth is machine-readable, updates propagate automatically.
The system doesn't forget to document a new endpoint. It doesn't let descriptions drift. The workflow becomes predictable: an engineer updates the spec, the pipeline regenerates the docs, a reviewer checks the diff, and the changes go live. For teams shipping API changes weekly, this is the only sustainable model. Manual documentation processes create lag between API changes and published content, and that lag is where trust erodes. Fern's analysis of API documentation maintenance found that drift between specifications, SDKs, and documentation is the primary failure mode for teams that treat documentation as an afterthought rather than as a component of the engineering workflow.
The structural advantage of automating from specs is that the automation is honest. It can only document what the spec describes. Which means the incentive structure changes: if an endpoint isn't documented, it's because the spec is incomplete, and that's a problem the engineer can fix. The documentation becomes a signal about spec quality, not a separate artifact that someone has to remember to update.
Doc Holiday generates API references and changelogs directly from OpenAPI specs and provides the structure for the validation and review layer that makes this workflow scalable for lean teams.


