Why Your Post-Mortems Don't Actually Prevent the Next Incident


The meeting ends, and everyone feels pretty good about it.
You sat in a conference room for an hour. You walked through the timeline of yesterday's database failure. You agreed that it wasn't Sarah's fault for running the migration, but rather a systemic failure of the deployment pipeline. You wrote down five solid action items. You filed the 12-page document in Confluence.
And then everyone goes back to work.
Six months later, at 2:00 a.m., the exact same system fails in the exact same way. The on-call engineer, who wasn't in that meeting six months ago, scrambles to figure out what's happening. The action items from the first post-mortem? They died quietly in a backlog somewhere, deprioritized in favor of shipping the new billing feature. The 12-page document? Nobody read it.
We have all been in this cycle. We run performative incident reviews that generate impressive artifacts and zero meaningful change.
If your post-mortems aren't producing operational change, you aren't doing reliability engineering. You're doing paperwork.
The Backlog Where Good Intentions Die
When an incident ends, there is a short window of urgency. The pain is fresh. People want to fix things. During that window, action items get written.
Then that window closes.
The action items go into a backlog. They sit next to feature requests and technical debt. Because product roadmaps rarely shift for invisible reliability fixes, those action items age quietly until the next incident — a pattern that repeats with near-mechanical regularity. The diagnosis is good, the action items are clear, and the follow-through is nonexistent. Not because the team forgot, but because there was no path from "we agreed to fix this" to "this is actually fixed."
There are predictable reasons why post-mortem action items fail. They lack a named owner. They live in a separate spreadsheet instead of the team's actual task tracker. They are vague wishes rather than concrete tasks. Nobody checks on them at sprint planning. And the systemic problems — the ones that require leadership authority to resolve — get framed as engineering tasks and quietly dropped.

"The team should improve monitoring" is not an action item. It is a sentiment. When ownership belongs to a team, it belongs to nobody.
"Alice will add an alert for database replication lag greater than 30 seconds in Datadog by the end of Sprint 14." That is an action item. It has a named owner, a verifiable verb, a specific outcome, and a deadline. Anyone can look at it and determine whether it is done.
The difference between those two statements is the difference between a post-mortem that drives change and one that produces nothing.
For systemic issues — the kind that require restructuring team ownership, changing incentive structures, or adding headcount — the formula is different. Name the specific gap. Quantify the consequence. Propose a concrete solution. Assign it to someone at the right organizational level, not "the team." Give it a deadline. A named VP with a specific request will get further than an action item that says "resolve ownership ambiguity," as Google's SRE team has documented in their guidance on postmortem action item planning.
Actions survive on rhythm, not good intentions. Review open post-mortem items at sprint planning. Have the incident owner send a two-week nudge. Give leadership a dashboard of open items. Two minutes per ceremony keeps follow-ups alive.
Stop Fixing People and Start Fixing Systems
We talk a lot about "blameless" post-mortems. The idea, popularized by Etsy and later codified in Google's SRE practices, is that human error is a symptom of systemic vulnerability, not the cause of failure. Etsy's foundational write-up on the subject makes the case plainly: if you punish the engineer who pushed the bad config, people will hide their mistakes next time. The cycle of name, blame, and shame produces cover-your-ass engineering, which produces more incidents — a dynamic Google's SRE book addresses directly.
But blamelessness often mutates into vagueness.
Teams become so afraid of pointing fingers that they fail to accurately describe what happened. The post-mortem becomes a CYA document in the other direction. It describes the failure so abstractly that the next person debugging a similar issue has no idea what to watch for. Findings like "insufficient monitoring" and "unclear ownership" appear in every post-mortem, for every incident, and fix nothing.
The goal is to be specific about what broke and why, while framing findings as system problems rather than character flaws. That requires understanding the difference between the "first story" and the "second story" of an incident — a distinction Etsy's engineering team developed in practice. The first story is what the logs show. The second story is what the engineer was thinking, what information they had, what made their decision reasonable at the time. A post-mortem that only captures the first story misses the most useful learning.
Accountability is forward-looking; blame is backward-looking. Assigning ownership of a fix is not the same as assigning fault for the incident. When you name this distinction explicitly in the room, engineers are usually willing to volunteer for follow-ups. They want to fix the system. They just don't want to be punished for its current flaws — a principle PagerDuty's blameless postmortem guidance reinforces.
A few structural choices make this easier. Ask "what" and "how" questions during the review, not "why." "What led you to investigate the cache first?" opens up honest discussion. "Why didn't you check the database?" shuts it down. Start your timeline analysis at a point before the incident and work forward, rather than backward from the failure. This counters hindsight bias — the tendency to see the outcome as inevitable once you know what happened.
The timeline itself is worth getting right. A good incident timeline is not just a log of events. It captures decision points: what information was available at each moment, what hypotheses were active, what made the wrong path look reasonable. "Database went down at 14:32" is a fact. "At T+12 minutes, we investigated the wrong service because alert routing pointed to the legacy dashboard" is a learning — the kind of second-story detail that Uptime Labs' post-incident review guide identifies as the most actionable output of a well-run review.
Contributing factors are also worth categorizing carefully. A finding of "missing alert" suggests a different remediation path than "unclear ownership" or "insufficient testing." When you group contributing factors by category — detection gaps, process gaps, architectural vulnerabilities, communication failures — the remediation work becomes clearer. Each category points toward a different kind of fix. Detection gaps suggest alerting work. Process gaps suggest runbook updates or ownership clarification. Architectural vulnerabilities suggest engineering investment. The categorization is not bureaucracy; it is how you make the action items legible to the people who will prioritize them — an approach the Google SRE Workbook formalizes in its postmortem culture chapter.
Closing the Loop Before the Next Page
Most post-mortems live in Confluence or Google Docs. They never make it into the runbooks, the monitoring configs, or the onboarding materials.
A 2025 empirical study of how engineers learn from failures at high-reliability organizations found that structured processes for learning from failures are often informal and ad hoc. Systemic barriers — time constraints, documentation gaps, and team turnover — limit effective learning. Recurring failures persist despite general process adherence. This is not a problem unique to small teams. It happens at organizations with excellent engineers, mature processes, and leadership that genuinely cares about reliability.
Knowledge transfer is something every engineering organization believes they do well, and almost none actually do. The engineer who knows how to fix the weird cache invalidation issue goes on vacation. The runbook is six months out of date. The next on-call engineer follows the stale steps and makes the situation worse. The loop is never closed.
The best post-mortem conclusions get encoded into the systems that would have prevented the incident. Updated alerting thresholds. New CI checks that catch the class of error that caused the outage. Architectural guardrails that make the failure mode impossible. Explicit runbook steps that the next on-call engineer can follow under pressure without needing to know the history.
If you are relying on engineers to manually update wiki pages after an incident, your documentation will decay. It is inevitable. The pressure to ship features will always override the pressure to maintain docs. The Jira ticket marked "documentation needed" will sit in the backlog until someone closes it without doing the work, or until the next incident makes it relevant again.
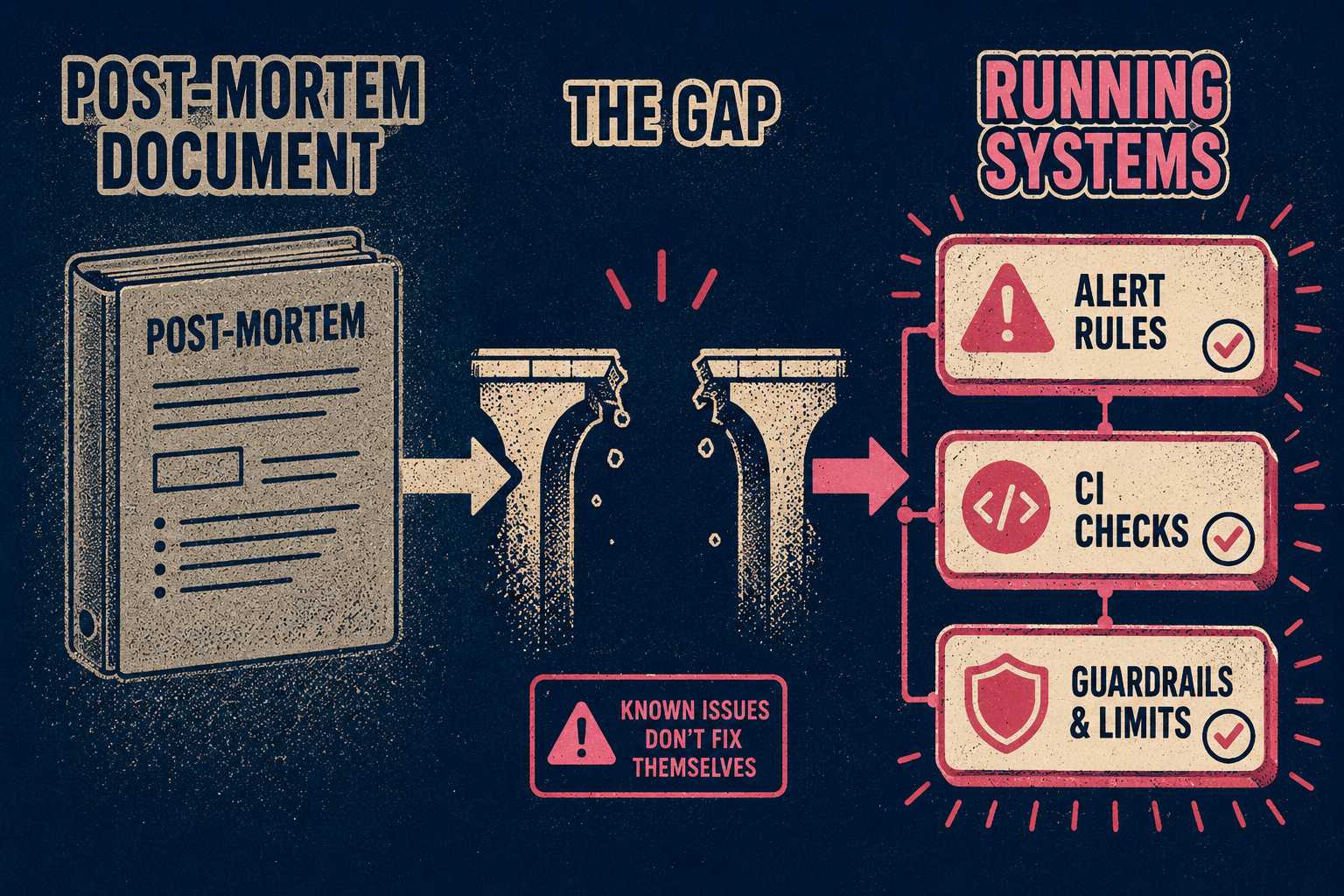
This is where the operational problem becomes concrete. A post-mortem is not finished when the document is filed. It is finished when the findings are encoded into the systems that prevent the next failure. That means updated runbooks, not just linked from the post-mortem but actually updated. It means new alerting rules deployed, not just described in an action item. It means CI checks that enforce the architectural constraint that the incident revealed.
Doc Holiday generates release notes and API documentation directly from engineering workflows, which means post-mortem findings that result in system changes — new config rules, updated APIs, architectural shifts — can be surfaced through deliberate human curation into the documentation engineers actually reference. Someone still has to decide which findings matter and how they're presented; the platform provides the structure so that decision doesn't get lost in a ticket marked "documentation needed." The learning actually lands.


