What Does a New Engineer Actually Need to Run an Unfamiliar System Within One Week?


A new engineer sits down on Monday morning. They have a laptop, access to the repo, and a ticket to deploy a minor change. They don't know the system yet. They look for the documentation, and they find a six-month-old Notion page detailing the system architecture. It has a nice diagram. It explains the philosophical reasons why the team chose Postgres over MongoDB.
It does not explain how to actually push the code.
It does not explain what to do if the deploy fails. It does not explain how to roll back. So, the new engineer Slacks three different people, waits two hours for replies, and eventually reverse-engineers a deployment script they found in a forgotten folder. This is not a failure of the new engineer. It is a failure of documentation design.
The reality of most system documentation is that it is either missing, stale, or organized for reference rather than execution. Developers already spend up to 70% of their time just trying to comprehend existing systems. When the documentation is organized around concepts instead of tasks, that number climbs. A one-week ramp means the docs have to be structured around what someone needs to do, not what someone needs to know.
To get an engineer to "minimally dangerous" fast—able to execute standard operations safely and know when to escalate—you need documentation structured for execution.
How to Actually Run the Thing
The first layer is the runbook.
This is not an architecture diagram. It is a task-first operations guide. What commands do you run? What does success look like? What does failure look like? What is the rollback procedure?
If it is not executable by someone who doesn't know the history, it is not a runbook.
Runbooks are the stopgap manual operations for things that should be automated but haven't been yet. They are the difference between a ten-minute fix and a two-hour outage. When you hand a runbook to someone who has never seen the system, they should be able to deploy a change safely. If they are Slacking you after ten minutes, your docs are reference material, not operational guides. Every interruption costs a developer an average of 23 minutes to fully rebuild their focus, which means a single undocumented procedure can cost the team far more than the time it would have taken to write it down.
The Context That Matters
The second layer is the system context brief.
Why does this system exist? What problem does it solve? What are the major components and how do they interact?
This should be short. One page if possible. It should connect directly to the runbooks. The new engineer should be able to read this, understand the basic shape of the thing, and then immediately start executing tasks. Deep system knowledge comes later. The goal right now is safe execution.
Google's SRE team learned this the hard way when bootstrapping a new team to go on-call within three months. The training roadmap they built was not a reading list—it was a checklist of executable tasks: administering production jobs, rolling back a bad software push, draining traffic away from a cluster (Google SRE Workbook). Context was provided in service of those tasks, not as a prerequisite to them.
What Breaks When You Break This
The third layer is the dependency map.
What does this system rely on? What relies on it? Where are the credentials? What breaks if this goes down?
This is often the missing piece. New engineers can follow a runbook, but they don't know what else will break if they take the wrong action. This is the bus factor in action—the risk that critical knowledge is concentrated in too few people. When a senior engineer is the only one who knows the dependencies, they become a single point of failure. They also become the person who gets paged at 2 a.m. when something breaks.
Documenting dependencies is how you stop being on-call forever.
What Normal Looks Like
The fourth layer is the operational baseline.
What does normal look like? What metrics matter? What is a real incident versus normal noise?
New engineers need to know what "good" looks like before they can recognize "bad." Observability is about understanding what is happening inside a system based on the data it produces. But raw data is useless if you don't know the baseline. If CPU usage spikes to 80%, is that a crisis or just the daily batch job? The documentation needs to define normal, or the new engineer will either ignore real alerts or escalate noise.
The Maintenance Trap
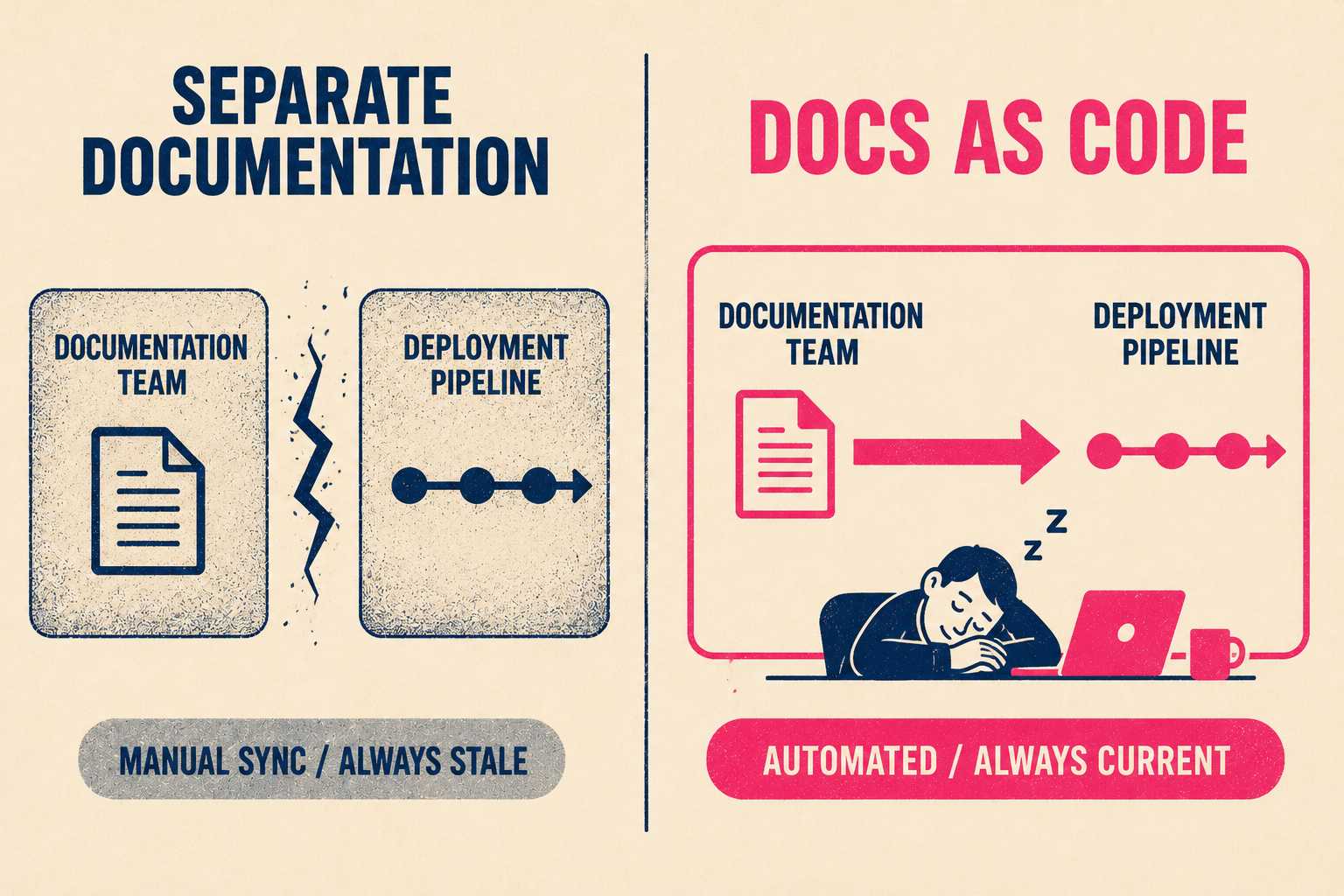
If documentation isn't tied to the deployment process, it goes stale immediately.
This is the structural problem. Engineers are good at writing runbooks when they have time. But they rarely have time. Research on documentation practices in continuous software development found that documentation going out of sync with the software is one of the primary challenges in agile and DevOps environments—and that the only reliable mitigation is executable documentation generated from development artifacts rather than written separately.
The teams that solve this are the ones that treat runbook generation as part of the build process, not a separate documentation project. When a new service gets deployed, the documentation should update automatically. If a configuration changes, the runbook should reflect it without a manual ticket. This is the "docs as code" philosophy—treating documentation just like software code, integrated into the CI/CD pipeline. Spotify's Backstage platform, for example, was built on exactly this principle: engineers write documentation in Markdown files that live alongside the code, and the CI system renders them automatically.
When deployment automation can generate the operational guide directly from the pipeline, you get runbooks that are always current and always structured for execution. Doc Holiday generates candidate runbooks, deployment steps, dependency maps, and rollback procedures tied directly to the release process—structured for a senior engineer to validate and refine rather than write from scratch.


