Keeping API Reference Documentation Synchronized With Production Deployments


You are sitting in a post-mortem on a Thursday afternoon. The root cause of the integration failure is already known. On Tuesday, a team deployed a change to the /orders endpoint, altering a required parameter from an integer to a string. The code worked perfectly. The tests passed. The deployment was flawless.
But the public API documentation still says it's an integer.
A major customer built an integration on Wednesday using the published documentation. Their requests failed. Their developers got frustrated. Your support team spent four hours diagnosing an issue that wasn't a bug, but a lie.

This is API drift. It happens when what you build diverges from what you publish. And it erodes trust in ways that show up as support load, developer churn, and integration failures.
When your specification drifts, it stops being a source of truth. This leads consumers down the wrong path, resulting in lost productivity or worse implementation issues.
The question isn't whether your docs will drift. They will. The question is how you build a system that catches the drift before your customers do.
How The Drift Actually Happens
Drift usually starts small. A developer adds an optional query parameter to handle a specific edge case. They intend to update the documentation later, but "later" never comes. Or a team deprecates an endpoint in the code, but the documentation repository is owned by a different team, and the ticket gets lost in the backlog.
Sometimes, the root cause is a lack of visibility. Architects simply do not have visibility into the gaps between production APIs and their associated specifications. When technology leaders cannot see how production deviates from specifications, it is challenging to determine what needs to change.
Other times, it is a lack of comprehensive testing. If there are no clear tests checking whether what is built actually matches what is described, code gets duplicated, and the chasm widens.
Whatever the cause, the result is the same. The OpenAPI description doesn't match reality, and so neither do the docs, the SDKs, or anything else.
The Mechanical Layer That Actually Prevents It
You cannot fix an operational problem by asking people to try harder. You fix it by changing the mechanics of how the work gets done.
The first step is moving to a schema-first or code-first development pattern. Whether you use OpenAPI for REST or GraphQL introspection, the documentation must be generated from a machine-readable source of truth. If a human has to manually copy and paste parameter definitions from a codebase into a CMS, you have already lost.
But generating the schema isn't enough. You have to enforce it.
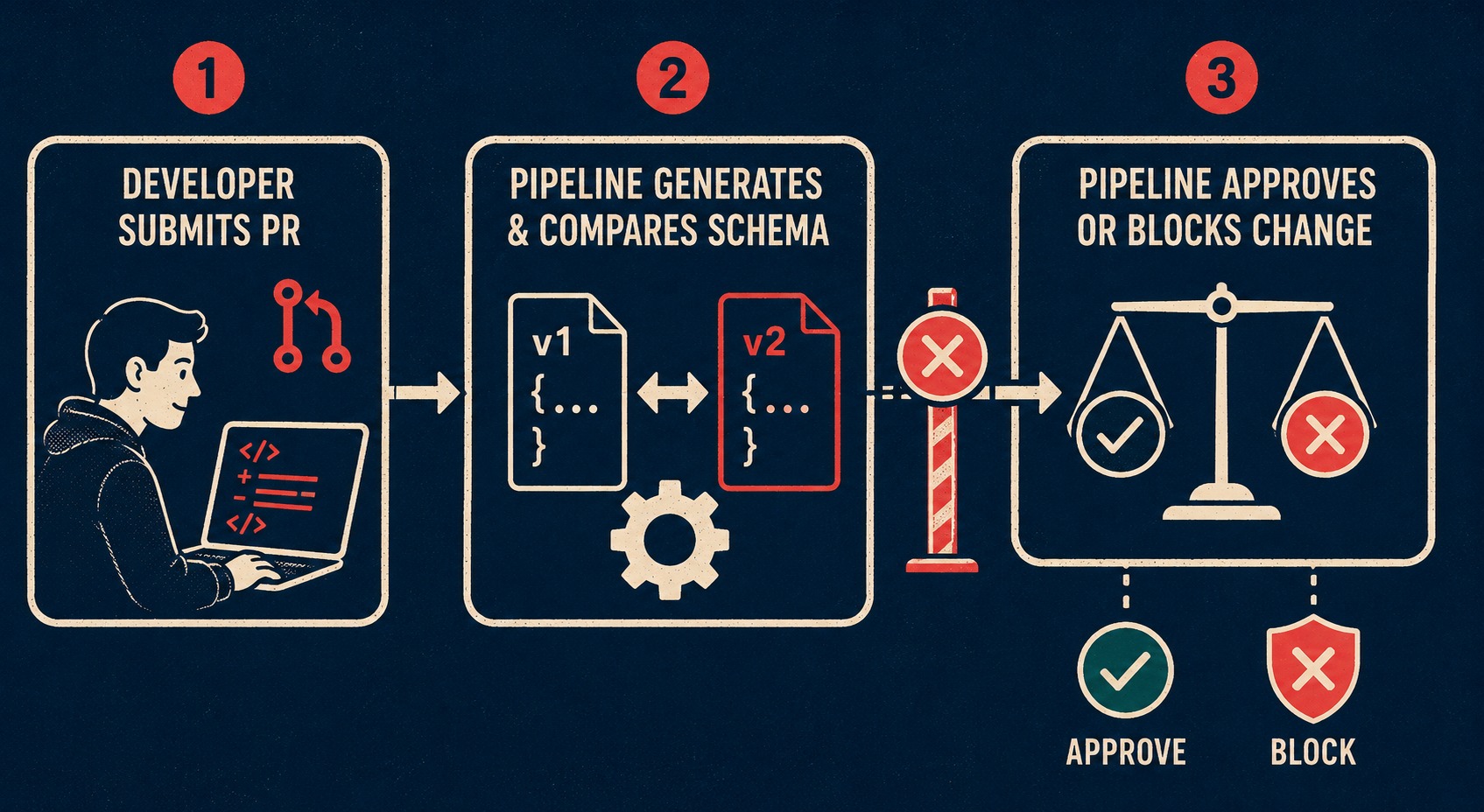
This is where the CI/CD pipeline comes in. You can automate the generation of OpenAPI documentation and keep it in sync with your code. More importantly, you can safeguard against API-breaking changes.
When a developer submits a pull request, the pipeline should generate the new schema and compare it to the existing one. Tools like oasdiff can automatically detect if the changes are breaking, as Harrison discusses in his article on detecting breaking changes in OpenAPI specifications. If a developer removes a required parameter or changes a data type, the pipeline fails the build.
You can also use contract testing to ensure that the API actually behaves the way the schema says it does. Contract testing verifies interactions between a consumer and a provider, ensuring that the API contracts are honored. If the production API returns a string when the contract promises an integer, the test fails.
These mechanical layers prevent the worst failures from reaching production. They catch the integer-to-string changes before the customer does.
The Part Automation Can't Do
Automation handles the mechanics. It ensures the parameters match and the data types align.
But automation cannot tell you if the description of the endpoint actually makes sense. It cannot tell you if the new query parameter is documented in a way that a third-party developer will understand.
This is where teams often make a critical mistake. They assume that because the documentation is auto-generated, they no longer need human oversight.
Auto-generated documentation tools focus on delivering basic information without considering the user's need for clear, step-by-step guidance. They list the technical details, but they do not explain how or why to use them.
You still need a skilled technical writer or a senior engineer to review the output. But their job changes. They are no longer doing the mechanical work of updating parameter tables. They are doing quality assurance on the system. They are validating that the auto-generated descriptions are accurate, that edge cases are documented, and that breaking changes are called out clearly.
Unmanaged automation produces technically accurate but functionally useless documentation. Managed automation scales quality.
The Versioning Problem Nobody Plans For
Even with perfect automation and rigorous human oversight, you still have to deal with time.
APIs change. You will eventually need to introduce breaking changes. And when you do, you have to manage the transition.
Supporting multiple API versions simultaneously increases costs and operational overhead. But forcing immediate upgrades breaks customer integrations.
You need a versioning strategy.
You can use API evolution, maintaining a single version and making non-breaking changes, only creating new endpoints for breaking changes. Or you can use explicit versioning, creating discrete API versions with clear boundaries (like /v1/ and /v2/).
Whichever you choose, you need a deprecation timeline. A typical timeline might include a 6-month announcement period, 12 months of active migration support, and 18-24 months total before removal.
Your documentation has to reflect this reality. It needs to clearly show which endpoints are deprecated, when they will be removed, and what the migration path is. It needs changelogs that surface exactly what changed between versions.
Letting The Pipeline Feed The Docs
The goal is not just to keep the documentation updated. The goal is to build a system where the documentation updates itself as a natural byproduct of the engineering workflow, with human oversight applied only where it adds the most value.
If your team has already built CI/CD automation, the next step is letting that automation feed documentation generation, not just testing and deployment.
This is what Doc Holiday is built for. It is a documentation engine that connects directly to your code base and product specs. It generates first drafts of release notes and API references automatically from code commits. But it is not an unmanaged black box. It provides the structure for a senior writer to review the output in a dashboard, validate accuracy, flag edge cases, and ensure the company's voice is consistently delivered. It gives lean teams the operational model to scale their documentation output without scaling their headcount.


