How to Write Release Notes for Infrastructure Changes That Directly Affect Customer Experience


If you migrate your database to a new cluster over the weekend, and a customer's query latency drops by 40%, did the migration really happen if you didn't tell them?
Yes, it did. And they noticed. They noticed because their dashboards loaded faster, or their automated reports finished earlier, or perhaps because their own monitoring systems threw an anomaly alert they couldn't explain.
Infrastructure changes sit at a strange boundary. They are, by definition, internal. They are the plumbing, the foundation, the invisible layer that makes the product work. But they are rarely entirely invisible. A CDN switch, an API gateway upgrade, or a shift in rate-limiting logic all produce real, behavioral changes that customers feel.
The problem is that infrastructure teams rarely write release notes for these changes. When they do, they write them for themselves. They describe the mechanism — "migrated Redis cluster to new availability zone" — rather than the outcome. The note satisfies the engineer who wrote it and confuses everyone else.
This gap exists because engineers think in terms of systems. Customers think in terms of symptoms.
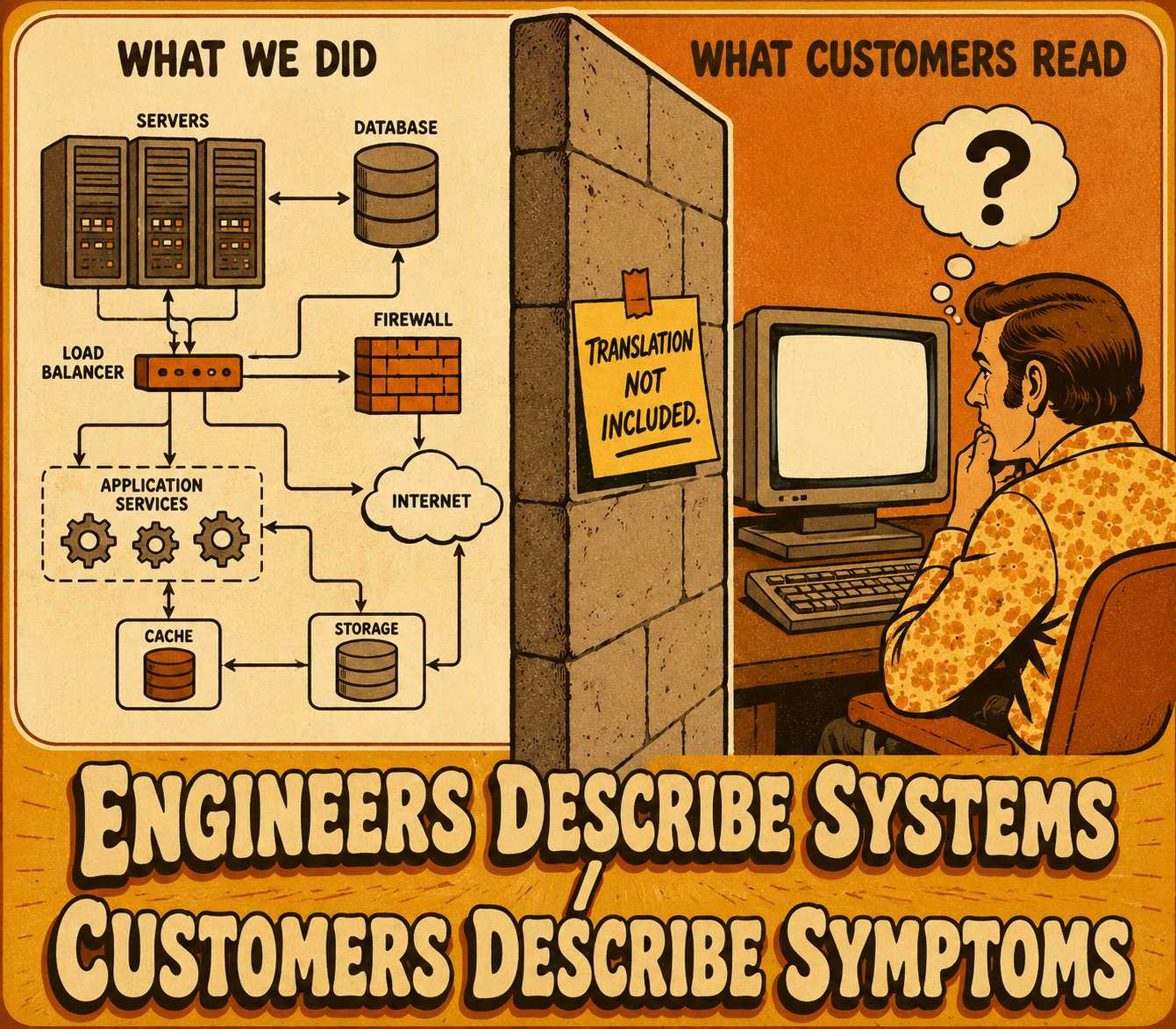
To write effective release notes for infrastructure changes, you have to bridge that gap. You have to start with what the customer feels, and work backward to what you did. That inversion is harder than it sounds, and most teams never quite manage it.
Where the Invisible Becomes Visible
Not every backend tweak needs a public announcement. Upgrading an internal monitoring tool or adding redundancy to a failover system that never triggers doesn't warrant an email blast. (Your customers will thank you for the restraint.)
The threshold for communication is observability. If a customer's monitoring, performance dashboards, behavior, or expectations would detectably change, it is a customer-facing event.
This includes changes to rate limits, DNS endpoint updates, shifts in retry behavior, or new error codes. It also includes performance improvements. If your database migration makes queries significantly faster, that is a change in behavior. Customers build their own systems around your performance characteristics. They write integrations that assume certain latency ranges. They set timeouts based on observed response times. If you change those characteristics without telling them, you force them to debug a problem that isn't actually a problem.
The distinction matters because it changes who needs to know and what they need to do. A rate limit change might require customers to update their retry logic. A DNS change might require them to update their firewall allowlists. A performance improvement might require them to recalibrate their monitoring thresholds. These are not passive changes. They have action items attached.
The test to apply is simple: would a customer's monitoring alert on this? If yes, it needs a release note. If a customer would open a support ticket asking "what changed?" it needed a release note yesterday.
Translating Architecture into Experience
The most common mistake in infrastructure release notes is leading with the architecture.
"Upgraded Kafka cluster to version 3.6 with improved partition rebalancing."
That tells the reader what happened. It doesn't tell them why they should care. It forces them to infer the impact on their own workflows, which most of them won't bother to do.
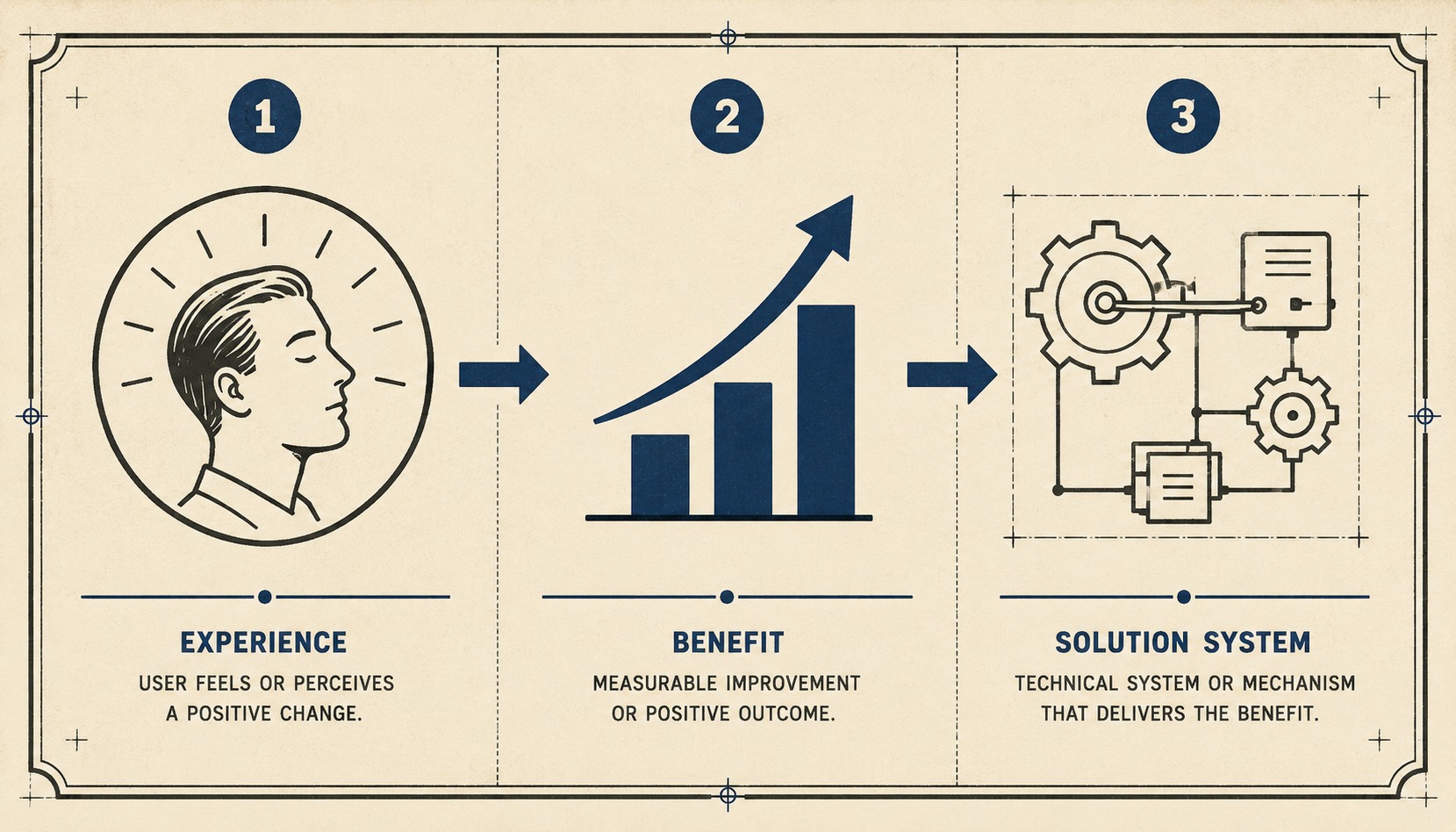
Start with the experience instead.
"Message delivery during high load is now more consistent. You may notice fewer temporary delays when publishing to high-throughput topics."
The second version answers the immediate question: What will I notice? It then provides the technical context for those who need it. This approach respects the reader's time. It gives them the outcome first, and the mechanism second.
The structure that works best is: immediate effect, then durable benefit, then technical detail. The immediate effect tells them what changes right now. The durable benefit tells them why this makes the platform better going forward. The technical detail, which can be placed in a collapsible section or a separate paragraph, gives engineers the specifics they need for their own documentation and integrations.
Atlassian's incident communication guidance makes a related point about clarity during disruptions: "explain the issue and how it impacts different stakeholders in layman's terms." The same principle applies to planned infrastructure changes. The stakeholders are different, but the need for plain language is identical.
The Anatomy of a Maintenance Window
Planned downtime is the ultimate customer-facing infrastructure event.
Customers will tolerate planned disruption. They will not tolerate surprises. When communicating a maintenance window, specificity is your best defense against frustration. Vagueness is not kindness. It is just a different kind of inconvenience.
A good maintenance note includes precise start and end times, complete with time zones. It details exactly which features or endpoints will be unavailable. It explains what error states or fallback modes the customer will see. It clarifies whether retries will work, or if they should pause their jobs entirely. And it defines what "back to normal" looks like, because customers need to know when to stop waiting.
If the maintenance window is the cost of a long-term reliability improvement, make that trade-off explicit. Tell them what they are buying with their patience. "This two-hour window allows us to migrate to a more resilient database architecture. After the migration, you will see improved failover behavior and reduced risk of data-layer outages during peak traffic." That is a sentence worth writing. It converts a disruption into an investment.
The table below shows the difference between a maintenance note that frustrates and one that informs:
The informative version is not longer because it is more thorough for its own sake. It is longer because each piece of information removes a question the customer would otherwise have to ask.
Writing for Two Audiences at Once
Infrastructure changes often matter to two distinct groups: the non-technical stakeholders who care about the business impact, and the engineers who need to integrate with your platform.
You have to write for both, without making either group wade through content that isn't for them.
The structure that handles this is progressive disclosure. The first paragraph summarizes the user-facing change and the benefit it provides. This satisfies the non-technical reader, who can stop there. The second section, clearly labeled as technical details, gives engineers the specifics they need: affected endpoints, error codes, retry behavior, required configuration changes, and any SDK or library updates.
This structure also has a practical benefit for the writer. It forces you to articulate the user-facing impact before you can retreat into technical description. If you can't write the first paragraph, you haven't yet understood what the change means to the customer. That is useful information.
Aha!'s release notes guidance describes this as "writing with customers in mind" and building narratives rather than lists. For infrastructure changes, that narrative is usually: here is what you will experience, here is why we made this change, here is what you may need to do differently.
Performance Metrics That Actually Matter
When documenting performance improvements, avoid marketing adjectives. Customers are skeptical of "dramatically faster" queries, and they should be. Vague performance claims are a genre of corporate writing that has trained readers to ignore them.
Be specific and measurable. Use percentile improvements rather than averages, because averages hide the tail behavior that most affects real users.
"Median query latency improved from 120ms to 75ms; p99 latency reduced from 890ms to 340ms under typical load."
This tells a precise story. It shows that you understand how performance is actually measured, and it gives the customer concrete numbers to verify against their own monitoring. As OneUptime's latency guide explains, p99 latency is where the worst 1% of requests live, and this is often where high-value traffic concentrates — checkout flows, admin operations, APIs under load. Improving p99 is a meaningful claim. "Faster queries" is not.
If the improvement is conditional, say so. "Median query latency improved from 120ms to 75ms for queries returning fewer than 10,000 rows. Queries returning larger result sets will see smaller improvements." That caveat is not a weakness. It is evidence that you actually tested the change under realistic conditions.
The same principle applies to availability claims. If you improved failover time, state the before and after. If you reduced error rates, give the percentage. Customers who are evaluating your platform against alternatives will remember specific numbers. They will not remember "improved reliability."
The Sound of Nothing Happening
Sometimes, an infrastructure upgrade goes perfectly. The load balancers are replaced, the traffic is routed, and the customer notices absolutely nothing.
These changes usually don't need external release notes. But occasionally, you need to document them for compliance, for customer audits, or simply because the change was significant enough that customers might wonder what happened to their monitoring graphs.
When you do, frame the success as the absence of change. "We upgraded our load balancers with zero downtime." It is a quiet flex. It acknowledges the work while confirming that the customer experience remained entirely stable. This framing is also honest: the goal of most infrastructure work is precisely that customers don't notice it.
A UX Collective guide to release notes quotes Google technical writer Sarah Maddox: "The most important function of release notes is to let customers know that something has changed in the product, particularly when that something may affect the way the customer uses the product." For zero-impact changes, the release note is essentially confirming that the thing that changed did not affect them. That is still useful information.
A Practical Checklist
Before publishing any infrastructure release note, run through these questions:
- Does the opening sentence describe what the customer will experience, not what you did?
- Have you specified which features, endpoints, or behaviors are affected?
- If there is a maintenance window, have you included precise times and time zones?
- Have you explained what "back to normal" looks like?
- If you are claiming a performance improvement, have you included specific percentile data?
- Have you stated whether any customer action is required?
- Is there a technical details section for engineers who need implementation specifics?
- Have you made the long-term benefit explicit, not just the immediate change?
If any of these answers is no, the note is not ready.
The Scaling Problem
Writing good release notes for infrastructure changes is difficult because it requires translating complex technical work into clear, outcome-focused language.
Doing this consistently across dozens of teams and hundreds of deployments is even harder. This is where the operational model breaks down for most organizations. They rely on engineers to remember to translate their commits into customer-facing prose, which is a bit like relying on surgeons to write their own discharge instructions. The expertise is there. The perspective is not.
A Pragmatic Engineer deep dive into Stripe's engineering culture describes its CTO framing operational excellence as "systematically keeping our promises to users." Release notes for infrastructure changes are part of that promise. They tell customers what changed, what they can expect, and what they need to do. When those notes are missing or unclear, the promise is broken, even if the infrastructure itself performed perfectly.
Doc Holiday addresses this by generating drafts directly from the engineering workflow. It pulls context from code commits and pull requests, providing a structured starting point that already contains the technical details. A human reviewer then refines the draft in a dashboard, shifting the focus from "what did we do?" to "what will the customer notice?" It gives teams the structure to validate and scale their documentation output without rebuilding a dedicated writing team for every infrastructure change.


