How to Run a Documentation Sprint That Doesn't Produce Garbage


You are staring at the Jira board. Down there at the bottom, sitting in the backlog like a forgotten piece of gym equipment, is a ticket labeled "Documentation Debt." It has been rolling over for six months.
Your engineers hate the current docs. Your users hate the current docs. You hate the current docs. So you decide to rip the band-aid off. You declare a documentation sprint. You block out two days, order a stack of pizzas, and tell the engineering team that nobody writes a line of code until the documentation is fixed.
It works, sort of. People type furiously. Markdown files are merged. The pizza is eaten. You declare victory.
Three weeks later, a new feature ships. The new documentation is now outdated. Three months later, the documentation you wrote during the sprint is actively misleading. The sprint didn't fix the documentation problem. It just created a new, slightly fresher pile of garbage.
This is the standard failure mode. We treat documentation like a one-time content project instead of an engineering knowledge capture exercise. We put people in a room who don't deeply understand the product and ask them to write about it. We establish no clear output criteria. We build no integration with existing workflows. And then we wonder why the output rots.
The good news is that documentation sprints can work. They just have to be designed as engineering events, not writing retreats.

The Pizza Doesn't Fix the Problem
The fundamental mistake is treating the sprint as a writing retreat. It is not. It is an engineering knowledge extraction event.
When you optimize for volume, you get surface-level descriptions of what buttons do. You get 50 pages of text that nobody will ever maintain. Research on software documentation quality consistently shows that the most useful documentation artifacts for maintenance are not comprehensive narratives but precise, scoped reference materials that answer specific questions. A sprint that produces 200 pages of loosely organized prose has not solved anything.
If you want a sprint that actually works, scope it ruthlessly. Solve one documentation gap completely rather than surface-coating everything. If the API reference is broken, fix the API reference. If the onboarding guide is a disaster, fix the onboarding guide. Pick the gap that is costing your users the most time, and close it completely.
Set the acceptance criteria before anyone touches a keyboard. What does "done" mean? Who decides? The Agile definition of done exists for exactly this reason. If you don't know how to measure the quality of the output, you are just typing for the sake of typing.
Who Actually Belongs in the Room
The instinct is to throw the whole engineering team at the problem. This is wrong.
The right participants are the people who built the feature or maintain the system, paired with someone who can structure and validate what they produce. Engineers carry the tacit knowledge — the undocumented reasoning behind design decisions, the edge cases that never made it into the ticket, the things that are "obvious" to anyone who was in the room when the feature was built. Research on software documentation issues identifies this knowledge gap as a primary driver of documentation failure. Without it, you are writing a description of a black box.
If you have a strong technical writer, they should not be drafting from scratch. They should be running the sprint structure, asking the right questions, validating the output, and ensuring consistency. The writer's job in a sprint is to be the person who turns engineering knowledge into something a user can actually follow.
Many organizations are operating with significantly reduced documentation teams. Snowflake, Amazon, and others made strategic cuts to centralized documentation headcount in 2025 and 2026. In that context, a sprint has to be designed around the resources that actually exist. The solution isn't to wait for headcount to return. It's to structure the sprint so that engineering knowledge gets captured by the people who have it, and validated by someone who knows how to organize it.
A survey of over 2,100 developers found that 41% cited insufficient documentation as a significant source of time loss, and that developers lack the time or desire to write the documentation they need. That is the real problem the sprint has to solve: getting the knowledge out of engineers' heads without making engineers into full-time writers.
When the Problem Isn't the Writing
Sometimes you get into a sprint and realize that the problem isn't a lack of content. It's a lack of structure.
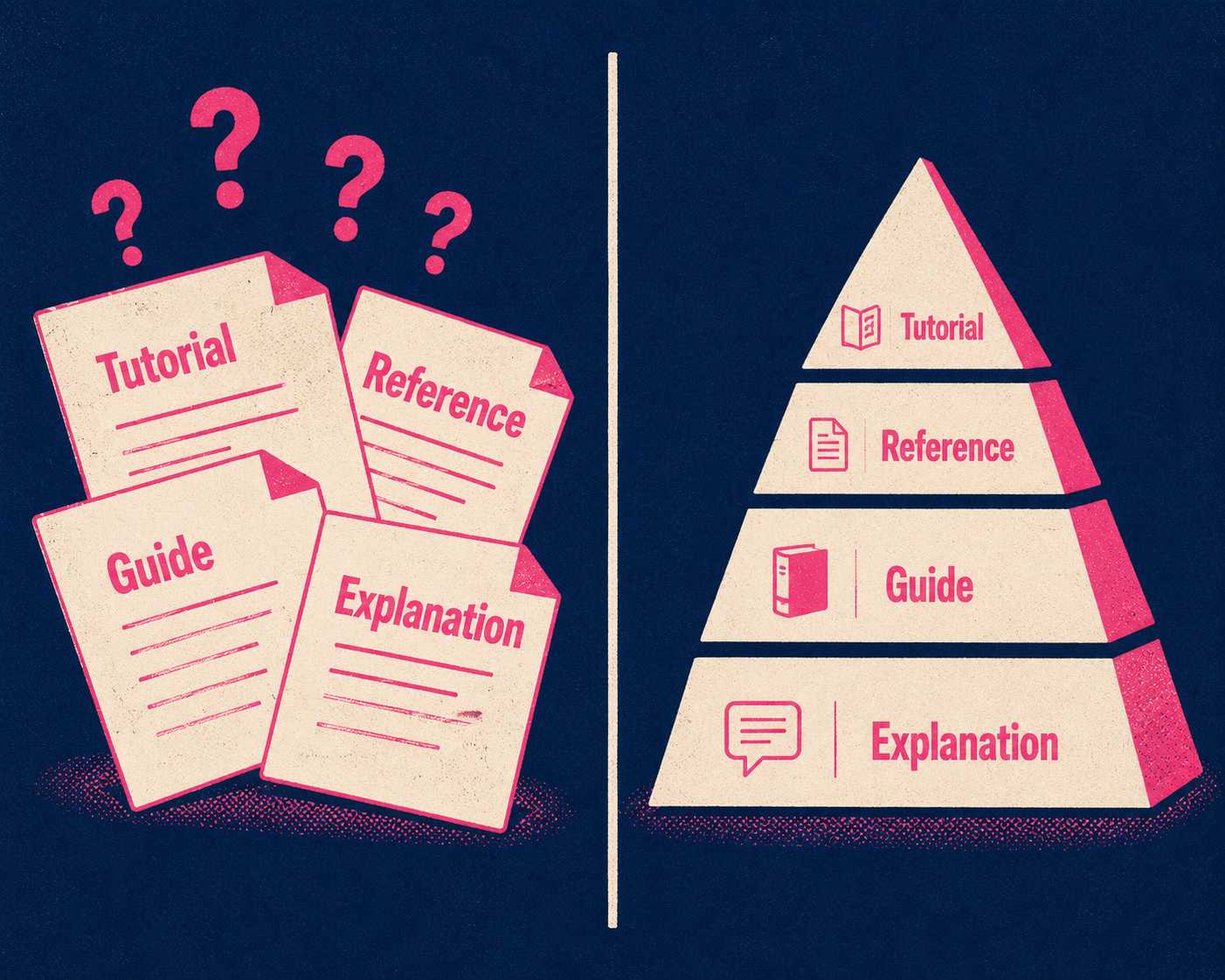
Nobody knows what the documentation is supposed to do. Is it an onboarding tutorial? An API reference? A troubleshooting guide? A conceptual explanation of how the system works? These are fundamentally different things, and mixing them up is one of the most reliable ways to produce documentation that nobody uses.
The Diátaxis framework identifies four distinct documentation types — tutorials, how-to guides, reference, and explanation — each serving a different user need. Cloudflare, Gatsby, and Vonage have all adopted it as a structural foundation for their documentation. The core insight is simple: if you don't know what kind of documentation you are writing, you will write bad documentation.
If the sprint uncovers that the problem is structural, stop writing articles. The output of that sprint should be a documentation architecture plan and a pilot implementation. Fix the skeleton before you start hanging meat on it. A sprint that produces a clear information architecture and one well-executed example of each documentation type is worth more than a sprint that produces 50 loosely organized articles.
Day Eight
The biggest risk of a documentation sprint isn't that the output is bad. It's that the output is obsolete within a release cycle.
Research on documentation staleness found that nearly 29% of the top 1,000 most popular GitHub projects contain at least one outdated reference to source code in their documentation — in projects where engineers are actively working in the codebase every day. The documentation from your sprint will face the same pressure the moment the next feature ships.
If your sprint is generating static Markdown with no maintenance plan, you are setting up the next failure. A good sprint produces the first version and the system that maintains subsequent versions. Google's internal engineering guidance makes this explicit: documentation should be treated like code, placed under source control, have clear ownership, and undergo review as the code it documents changes.
What happens on day eight? What happens when the sprint is over and the pizza boxes are thrown away?
If the answer is "nothing," the sprint failed.
The best documentation sprints connect the output to the engineering workflows that will update it. They produce pull request templates that prompt engineers to flag documentation changes when code changes. They produce changelog automation tied to commit messages. They produce API schema validation that catches documentation drift before it reaches users. The docs-as-code approach, now standard practice at companies like Google and GitHub, treats documentation with the same version control, review, and CI/CD integration as the software itself.
For lean teams, the sprint should set up automation and validation structures that allow a small team to manage ongoing accuracy without manually rewriting everything each release. That is where a tool like Doc Holiday fits into the picture. It generates the high-frequency material — release notes, changelogs, API docs — directly from engineering workflows. The sprint output becomes the framework that validates and governs it. The technical writer who ran the sprint becomes the person who ensures the automated system is producing trustworthy output, instead of being stuck rewriting the same content every cycle.
The sprint is worth running. Just make sure you're building a system, not a document.


