How to Fix Stale Onboarding Guides


A new engineer joins your team. They get their laptop, log in, and open the onboarding wiki. Step three tells them to run a deployment script that was deprecated six months ago. The person who knows the new process is currently fighting a fire in production. The new hire is stuck.
This is what happens when documentation is treated as an artifact maintained separately from the systems it describes. Every deploy, every architecture decision, every tool swap creates drift. The people who know what changed are busy shipping. They are not going back to update a Notion doc.

The structural answer is to generate onboarding content from the same workflows that create the changes. Not to try harder. Not to assign a better owner. To change where the content comes from.
Why the Usual Fixes Don't Work
When a guide goes stale, the instinct is to assign an owner. Make it someone's quarterly goal. Put it on a checklist.
This creates a bottleneck and a resentful maintainer. It also catches drift too late. If you audit documentation every quarter, new hires have already been confused for months. Making documentation a separate, manual task rarely sticks when velocity matters, because the people who know what changed are the same people who just shipped the change, and they have moved on.
Documentation drift is a well-documented problem: the help center or wiki falls out of sync with the product or codebase, and the gap between them widens with every release. It is a systemic problem of state drift. The cost is real. Research from developer experience teams puts typical onboarding at around four weeks with good documentation. Poor documentation stretches that to twelve weeks or more. New hires don't onboard slowly because they're unprepared. They spend their first weeks hitting dead ends in stale content and reverse-engineering systems that should have documented answers.
Google's research on developer onboarding found that the three top hindrances to ramping up were learning a new technology, poor or missing documentation, and finding expertise. Documentation was second on that list. Not tooling. Not codebase complexity. Documentation.
Where the Truth Actually Lives
The solution is to treat documentation like code. If your deployment pipeline knows what shipped, your API docs know what endpoints exist, and your runbooks know what is live, that is your source of truth. The onboarding guide should pull from those systems, not duplicate them.
This requires separating what changes constantly from what changes rarely. Tool versions, API endpoints, and deploy processes are volatile. Team philosophy, decision-making frameworks, and cultural norms are stable. These are different kinds of content, and they need different maintenance strategies.
For the stable content, write it once and version it like code. The docs-as-code philosophy, which applies version control, code review, and CI/CD pipelines to documentation, is exactly the right model for this layer. A team handbook that describes how decisions get made, what the architecture looks like at a high level, and why certain tradeoffs were chosen can live in a Git repository and be updated through pull requests. It doesn't need to be regenerated every sprint. It needs to be versioned and owned.
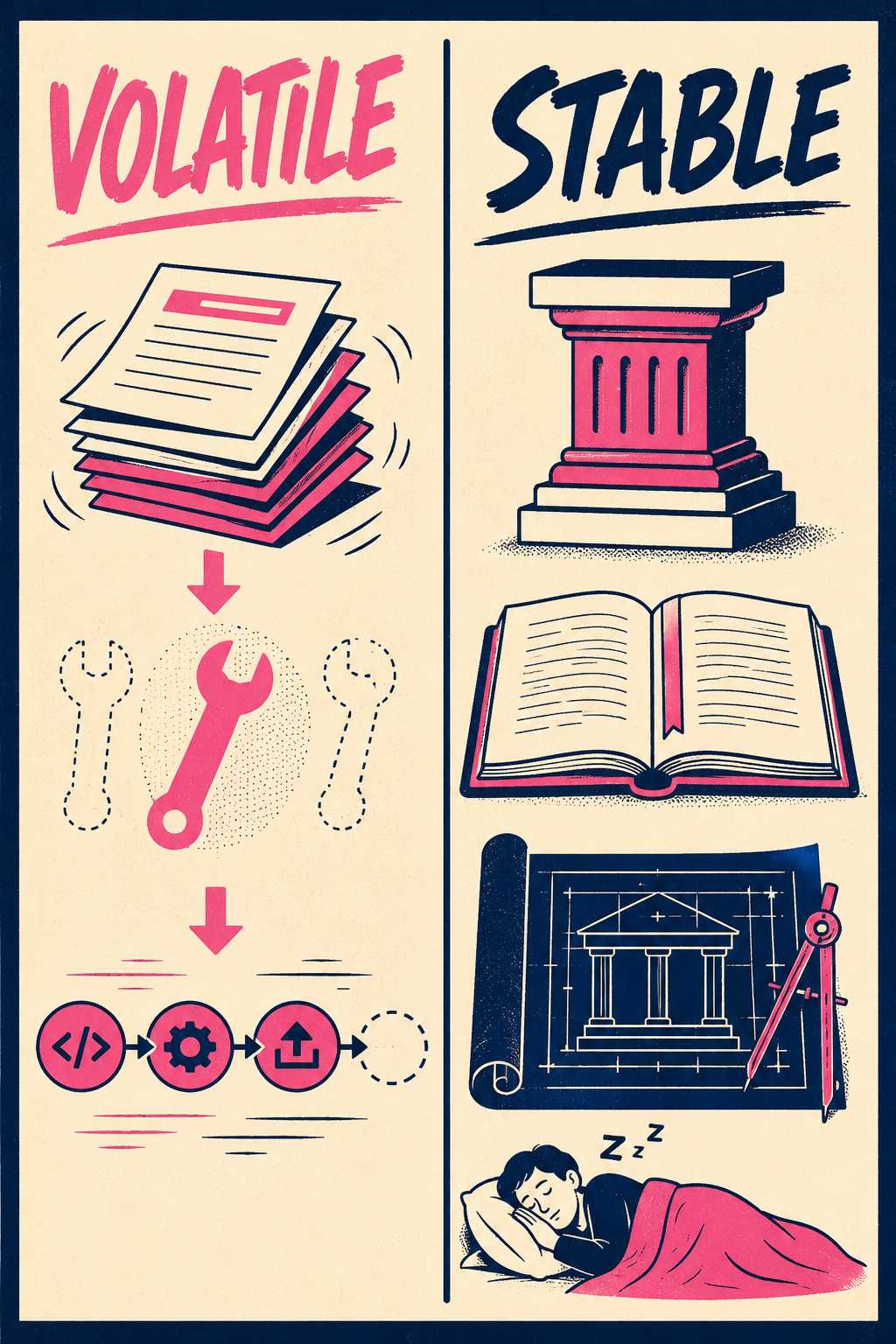
For the volatile content, generate it or link directly to the system of record. Do not copy-paste a list of endpoints into a guide that will be wrong in two weeks. Do not write a deploy walkthrough that will be outdated before the next hire reads it.
Architectural decision records (ADRs) are a useful tool for the stable layer. They capture the rationale behind choices, provide context-specific justifications, and outlive the initial design phase. AWS teams implementing ADRs found that development teams were spending 20 to 30 percent of their time coordinating with other teams, much of it because architectural context wasn't documented. ADRs are the kind of content that doesn't change every sprint. They are worth writing well.
What New Hires Actually Need to Read
Good onboarding guides contain two things: procedural accuracy and institutional narrative.
The "how to deploy" part is procedural. It changes constantly. It should be generated or linked. The "why we deploy this way" part is institutional. It is stable. It is worth writing well.
High-quality onboarding handbooks give new hires a view of what they can expect to learn and provide future resources. Shopify's engineering leaders describe the value of onboarding documentation in terms of context, not procedure: knowing where to find information, understanding the CI/CD pipeline, reading architecture and internal system designs. That is stable content. It does not need to be regenerated every sprint.
The procedural content is different. SmartNote's published research on automated release note generation notes that release notes take up to eight hours for an experienced developer to draft manually. At continuous delivery cadences, that is not sustainable. The same logic applies to any documentation that describes a system that changes on every deploy. If the content changes faster than a human can maintain it, the human is not the right tool for the job.
The Validation Layer
Some people argue that generated content feels impersonal and lacks context. This misunderstands the goal.
Procedural accuracy is handled well by generated content. Institutional narrative is written by humans. The combination works.
Even with generated content, someone should review it. Ideally, this is someone who recently onboarded and remembers what was confusing. This review is not about correcting technical drift. That is handled upstream, in the pipeline that generates the content. It is about narrative flow and missing context, the things a new hire needs to understand a system, not just operate it.
This is what Doc Holiday produces: documentation generated directly from engineering workflows, release notes, API references, and changelogs, with the structure to validate and manage that output without rebuilding a documentation team. The volatile layer is automated. The stable layer is authored. The validation loop is human. That is the operational model that actually scales.
Audit your current onboarding guide. Separate the parts that change every sprint from the parts that haven't changed in six months. Stop trying to manually maintain the former. Treat it like any other engineering dependency. Automate it or link to the source.


