How Should Companies Communicate Rate Limit Changes to API Users?


If you run an API, there is a specific kind of Tuesday afternoon that you dread. The servers are stable. Latency is low. The infrastructure dashboards are a soothing, uninterrupted green. But the support queue is suddenly flooded with angry developers. Their integrations are failing. Data is dropping. They are demanding to know why your API is broken.
Your API is not broken. It is doing exactly what it was told to do. Earlier that morning, someone on the infrastructure team lowered the default rate limit from 100 requests per second to 50 to save costs. They didn't change the payload. They didn't rename an endpoint. They just tweaked a configuration file, assuming it was an internal operational detail.
It was not an internal operational detail. It was a breaking change.

When a client application is built to expect 100 requests per second, and it suddenly hits a wall at 50, it doesn't gracefully degrade. It crashes. It drops webhooks. It fails to sync inventory. To the developer on the other side, a sudden HTTP 429 error isn't a gentle suggestion to slow down. It's a wall.
This is the hard reality of API management. Rate limits feel like infrastructure levers, but they are actually public contracts. Changing them affects production systems, catches developers mid-integration, and feels like a rug-pull if handled poorly. The stakes are real: broken integrations, churned customers, and support ticket floods.
So how do you change the rules without breaking the trust?
The Quietest Breaking Change
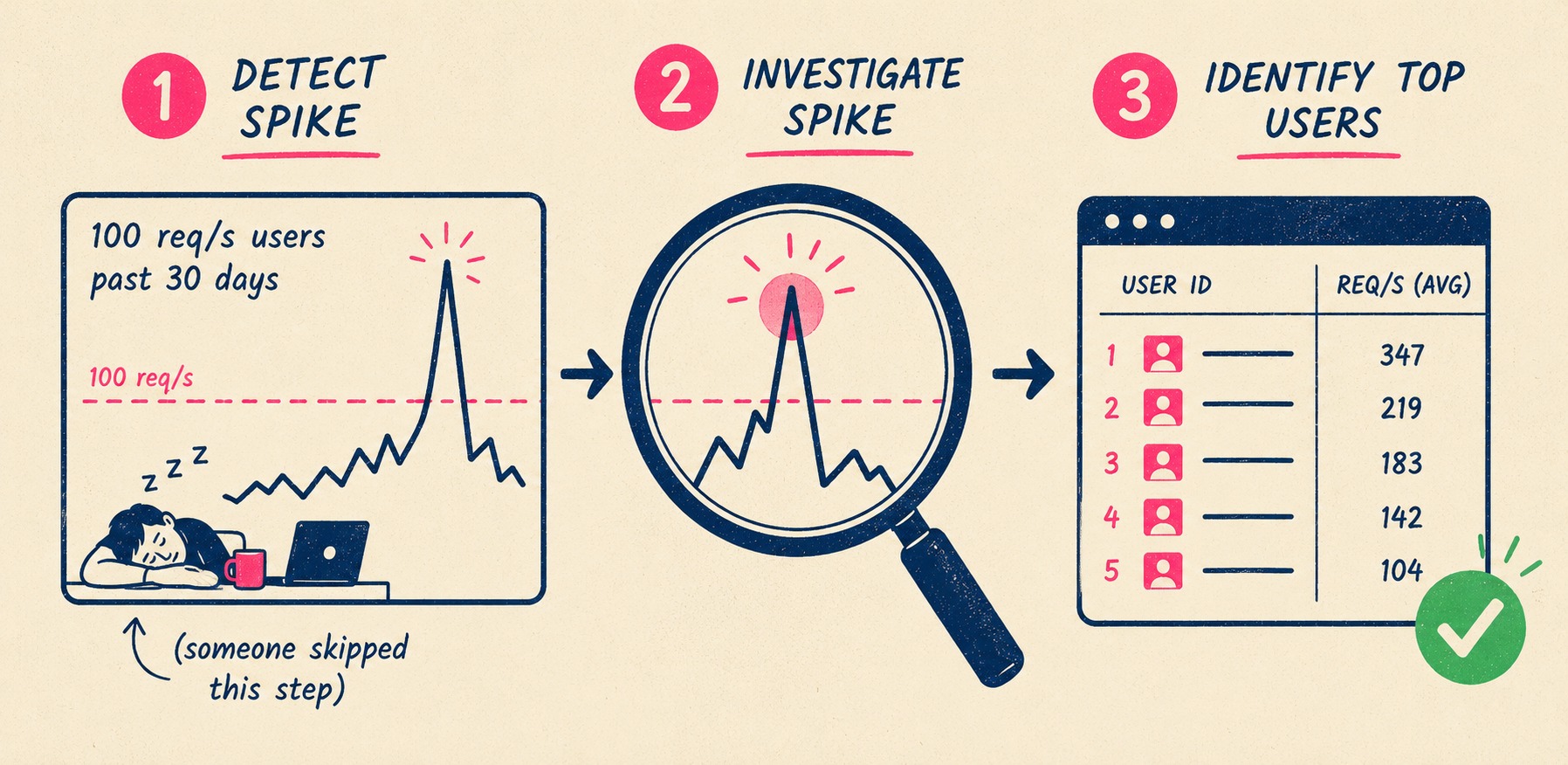
Before you announce anything, you have to know who you are about to break.
Most companies skip this step. They write a changelog entry, push the configuration change, and wait to see who complains. This is a strategy, I suppose, in the same way that driving with your eyes closed is a strategy for finding the edge of the road.
You have to look at the logs. If you are lowering a limit to 50 requests per second, you need to identify every single user who has exceeded 50 requests per second in the last thirty days. You need to understand their integration patterns. Are they spiking during batch jobs at midnight? Are they consistently running hot?
You cannot enter the announcement phase with just a warning. You have to enter it with answers. When a high-volume user gets the email saying their limit is dropping, their first question will be, "Does this break me?" You should already know the answer.
This means getting support, sales, and DevRel aligned on the messaging. If a major enterprise client is going to hit the new wall, their account manager should be the one telling them, not an automated email from a no-reply address.
The 30-Day Minimum
When you are ready to talk, you have to say the right things, in the right places, at the right time.
The specific change must be obvious. State the old limit. State the new limit. State the exact date and time it takes effect. Do not make them guess.
Explain why it is happening. Be honest. If it is for infrastructure cost control, say that. If it is for abuse prevention, say that. Developers understand that servers cost money and that bad actors exist. They do not understand vague corporate speak about "optimizing the platform experience."
Timing is non-negotiable. For a breaking change—and a rate limit reduction is a breaking change—30 days of advance notice is the absolute minimum. Sixty to ninety days is better. At enterprise companies, 90 days is standard because developers need time to read the announcement, schedule the work in a sprint, write the retry logic, test it, and deploy it. You cannot deploy a breaking change on a Tuesday and tell your customers about it on a Wednesday.
You also cannot rely on a single channel. Do not bury a rate limit change in generic release notes at the bottom of a changelog. Publish it in the changelog, yes. But also send an email to the technical contacts on the affected accounts. Put a banner in the developer portal. If you have an active community Slack or Discord, post it there. Redundancy is the only way to ensure the message survives the noise.
The Migration Scaffold
Telling developers they need to slow down is only half the job. The other half is helping them do it.
You have to provide scaffolding for the transition. This means code examples. Show them exactly how to handle the new limits gracefully. If you expect them to parse the Retry-After HTTP header—the standard mechanism for rate limiting defined in RFC 6585—give them a snippet in Python, Node, and Go that shows how to implement exponential backoff.
If possible, provide a testing environment where users can validate their changes before they go live. If they can't test their new retry logic against the lower limit in a sandbox, they are going to test it in production on the day you flip the switch.
Consider a graduated rollout. Instead of dropping the limit for everyone at once, drop it for 10% of users. Monitor the support queue. If things look stable, expand it. This canary approach reduces the blast radius if something goes wrong. And have a clear escalation path. There will always be a user who simply cannot meet the new limits without fundamentally re-architecting their system. Give them a way to request a temporary grace period.
When Things Break Anyway
Even with perfect planning, you have to keep communicating as the change rolls out.
Provide progress updates. If you have real-time dashboards showing current usage against new limits, expose them to the users. Reach out proactively to high-impact users who are still hitting the old limits a week before the deadline.
But what about the hardest case? What happens when you have to drop a rate limit immediately because of a severe infrastructure incident or a coordinated abuse attack?
When you have hours, not weeks, the minimum viable communication structure is a status page update and a direct email to the most active users. You explain the emergency. You explain the temporary limit. You promise an update within a specific timeframe. And when the dust settles, you publish a public retrospective. You explain what broke, why the limit was changed, and how you will prevent it from happening again.
Most companies execute all of this manually. They pull spreadsheets of affected users. They hand-write emails. They draft changelog entries in Google Docs and copy-paste them into a CMS. It is slow, error-prone, and exhausting.
Engineering-driven companies don't do this. They treat documentation as code. They tie their API changes to their communication artifacts. When Stripe introduces a new API version, the changelog is programmatically generated, and the documentation detects the user's API version to present relevant warnings. The communication is part of the infrastructure.
This is exactly the problem Doc Holiday is built to address. Rate limit changes show up in release notes, API references, and changelogs—outputs that Doc Holiday compiles directly from engineering workflows and surfaces for human review before publication. The platform gives teams the structure to validate those communications, catch gaps or inaccuracies, and ensure affected users actually see them, rather than relying on manual changelog updates that developers might miss. It turns a high-stakes communication problem into a repeatable, reviewable process.


