Documenting Multi-Tenant Architectures for Enterprise Buyers


It is 4:00 PM on a Friday. Your VP of Sales has just forwarded an email from a Fortune 500 prospect. Attached is a 150-question security spreadsheet. The deal is contingent on your team proving that if another customer on your platform gets breached, the prospect's data remains untouched.
The answers exist. Your team built a robust multi-tenant architecture. But the specific details about tenant isolation, failover boundaries, and data residency are scattered across Slack threads, a two-year-old Confluence page, and the minds of two senior engineers who are currently trying to ship a critical feature.
This is the reality of selling multi-tenant software to the enterprise. Buyers demand proof of architectural boundaries. When that proof is undocumented, sales cycles stall, and engineering teams get pulled into endless questionnaire reviews.

To satisfy enterprise auditors and security teams, you need to document specific architectural realities. You need to explain how your system separates data, contains failures, and enforces access. Here is what that documentation actually needs to cover.
What Enterprise Buyers Are Actually Asking
Enterprise security teams do not want to read your marketing site. They want to understand your tenant isolation model.
The first question is almost always about data separation. Are you using a shared database with row-level security, separate schemas per tenant, or entirely dedicated databases? If you use a shared database, they will ask how you guarantee that a bug in an API endpoint won't accidentally return Tenant A's data to Tenant B. This is not a hypothetical. It is the kind of question that kills deals when the answer is "we handle it in application code."
The second major area is data residency and sovereignty. If a European prospect requires GDPR compliance, your documentation must show exactly where their data lives, how it is segregated regionally, and whether they can enforce data locality. FedRAMP-bound prospects need to see documented boundary protection controls aligned to NIST SP 800-53, specifically SC-3, SC-7, and SC-39. These are not optional details. They are the evidence chain that compliance teams need to sign off on a vendor.
The third question is the one that makes engineers uncomfortable: what happens when something goes wrong?
The Blast Radius Problem
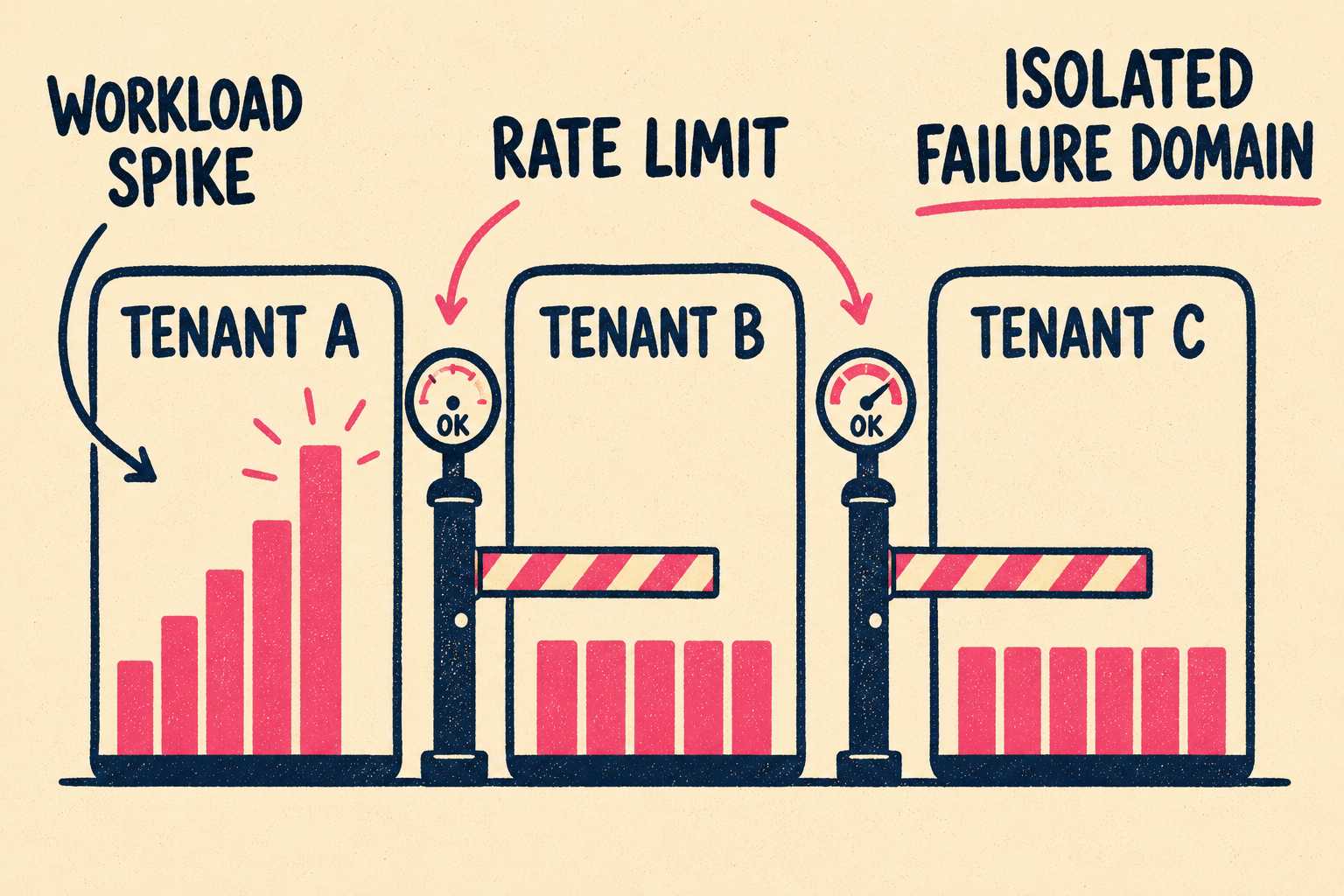
The noisy neighbor problem is one of the most persistent concerns in multi-tenant architectures. In a shared infrastructure, one tenant running a massive, poorly optimized query can consume all available CPU and memory, degrading performance for everyone else on the platform. Enterprise buyers know this. They have probably experienced it with a previous vendor.
Your documentation needs to explain your failure domains. If one tenant's workload spikes, what prevents it from cascading? The answer might be query throttling, per-tenant rate limits, Kubernetes namespace-level resource quotas, or dedicated capacity tiers. Whatever the mechanism, it needs to be written down.
The blast radius question extends beyond performance. Buyers want to know: if one tenant's environment is compromised, what is the architectural boundary that prevents lateral movement to other tenants? This is where documentation of your network segmentation, container isolation, and access control policies becomes critical. Logical isolation through application code is not enough. Buyers want to see enforcement at the infrastructure layer.
This is also where incident response documentation matters. What monitoring exists to detect cross-tenant impact? Who gets alerted, and on what timeline? How are incidents contained and communicated?
Proving Isolation Without Showing the Code
You cannot hand over your source code to an auditor. Instead, you prove isolation through access controls and audit trails.
Buyers will ask about your authentication boundaries. They need to see how tenant admins are isolated from each other. They want to know how API keys are scoped. If you use Role-Based Access Control (RBAC), document how roles are tenant-scoped rather than global. A user who is an admin in Tenant A should have zero privileges in Tenant B. This sounds obvious, but the role explosion problem in traditional RBAC implementations means it often isn't enforced correctly. Documenting your authorization model precisely is the difference between a confident answer and a vague one.
Compliance frameworks require evidence, not assertions. SOC 2's Trust Service Criteria and HIPAA's audit control standard (45 CFR § 164.312(b)) both require that you implement mechanisms to record and examine activity in systems that contain sensitive data. Aptible's guidance on audit log retention is worth reading carefully here: the regulation itself is only four words, but the implementation details are everything the regulation doesn't say. That means tenant-scoped logging, with immutable audit logs that capture who accessed what, when, and from where. HIPAA requires six years of log retention. GDPR requires that you can produce records on request. Your documentation should explain how your logging infrastructure meets these requirements, where logs are stored, who can access them, and how they are protected against tampering.
The audit trail is not just a compliance checkbox. It is the evidence chain that lets a SOC 2 auditor trace an activity from start to finish. If your logs are siloed across CloudWatch, RDS, and a third-party SIEM with different retention policies and no unified access control model, that is a documentation gap and an audit risk.
Where the Documentation Actually Lives, and Why It Keeps Breaking
Most teams store architectural documentation in Confluence, Notion, or Google Docs. The problem is not the tool. The problem is architectural narrative drift.
A system is built. A document is written. Six months later, the system evolves, but the document does not. The isolation model changes. A new regional deployment is added. A schema migration shifts the data residency story. None of this gets reflected in the whitepaper that sales is still handing to prospects.
Architecture Decision Records help capture the reasoning behind architectural choices, but they live in Git repositories that security teams and sales engineers rarely access. The knowledge is technically preserved, but practically inaccessible.
The result is that engineering teams end up re-extracting the same architectural knowledge every quarter. A new prospect sends a questionnaire. A senior engineer spends two days writing answers. The answers get filed in a deal folder and never updated. The next prospect sends a nearly identical questionnaire, and the process starts over.
Some of this documentation belongs in a public-facing security whitepaper, covering certifications, high-level isolation models, and compliance posture. Some of it belongs in inline documentation for sales engineering decks, tailored to specific buyer concerns. Some of it belongs in a formal architecture document for technical due diligence. But all of it needs to stay current.
The teams that handle this well are the ones that treat architectural documentation as a living artifact derived from the system itself, not a one-time writing project. If the documentation can be generated from the infrastructure definitions, deployment configs, and access control policies already in version control, and a technical writer or security engineer validates and adapts it for the enterprise audience, the documentation stays accurate and the sales cycle stays unblocked.
That is the operational model Doc Holiday is built around. AI generates first drafts from code commits and infrastructure definitions. A reviewer validates the output in a dashboard. The result is reference documentation that reflects the actual system, not the system as it existed when someone last had time to write about it.


