How Engineering and Product Teams Can Automate Their Product Changelog Generation


Your release is scheduled for tomorrow morning. Someone just pinged the engineering lead asking who is writing the release notes.
Nobody has started. Nobody wants to. The person who did it last time is on vacation, and the person before them left the company six months ago along with the custom script they built to pull PR titles into a Google Doc.
This is the actual problem with changelogs. Not that they're hard to write. It's that they require someone to stop what they're doing, sift through two weeks of merged pull requests, decide what matters to users versus what was an internal refactor, and produce something coherent before the release goes out. Documentation tasks consume roughly 11% of developers' work hours. When teams are shipping weekly, that's not a rounding error.

Automating your product changelog generation is the obvious answer. But making it actually work in production requires more than just pointing a script at your Git history. Teams that have tried and failed usually made the same mistake: they assumed the automation layer would compensate for the chaos upstream. It won't.
The automation layer cannot invent structure
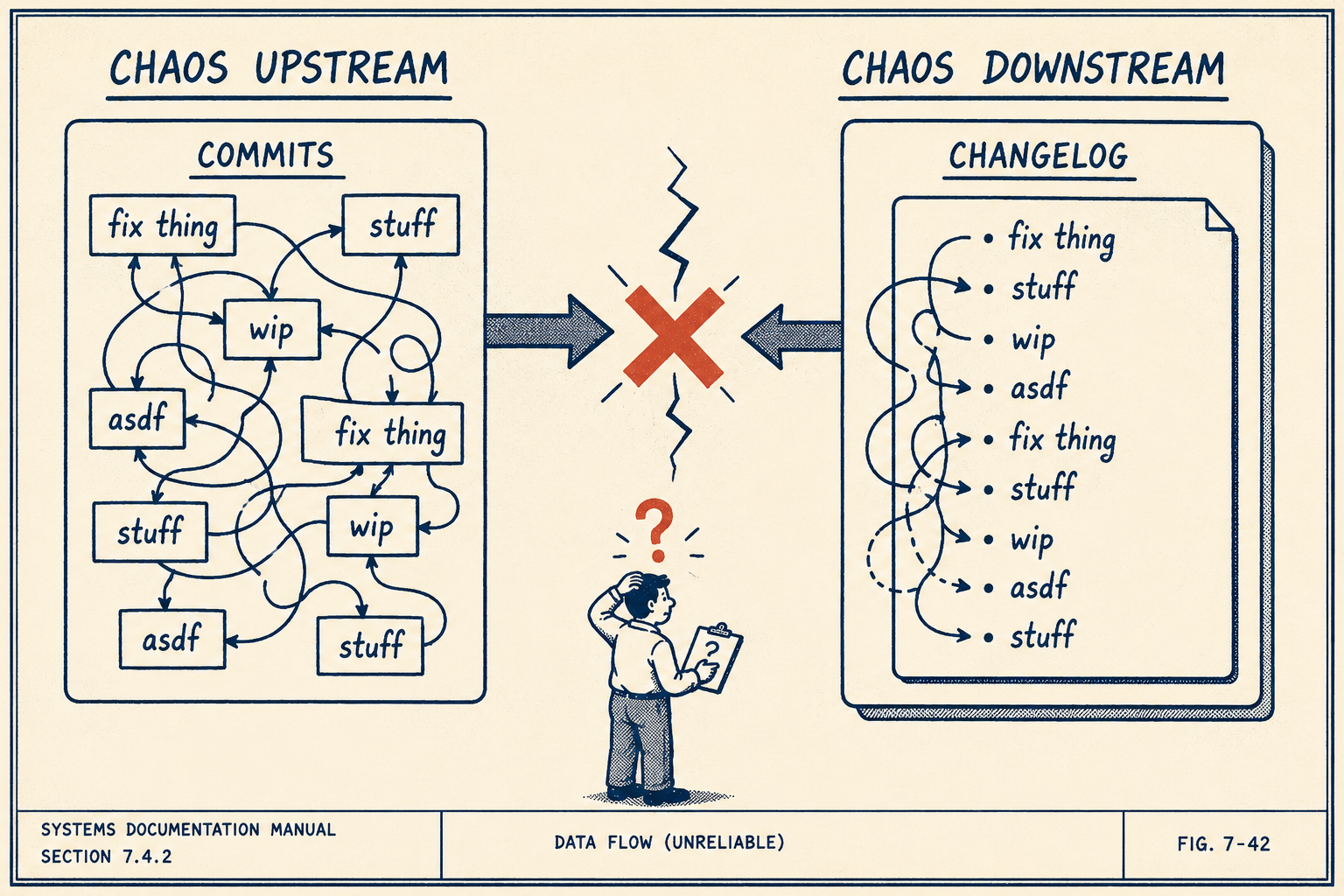
Before you can automate anything, you have to look at what exists upstream.
If your commit messages say "fix thing" and "update stuff," your automated changelog will say "fix thing" and "update stuff." The automation layer cannot invent structure that doesn't exist. This is the single most common reason changelog automation fails in practice.
A 2022 study of nearly 1,600 commit messages across five highly active open source projects found that an average of 44% of messages could be improved. That's the raw material your automation pipeline is working with.
Organizations that ship reliable automated changelogs enforce strict upstream practices. They use Conventional Commits to standardize commit messages with prefixes like feat:, fix:, and BREAKING CHANGE:. The spec maps directly to Semantic Versioning, so fix: commits become patch releases, feat: commits become minor releases, and BREAKING CHANGE: commits trigger major version bumps. This gives the automation pipeline enough signal to determine what changed and how significant it was.
Beyond commit messages, PR descriptions matter. Teams that produce good automated changelogs require a "User Impact" field in their PR template. They link every PR to a structured ticket in Jira or Linear. Research analyzing release note content found that the most valuable artifacts are pull requests (32% of content), issues (29%), and commits (19%). That data is already in your systems. The question is whether your team is disciplined enough to put it there.
When the source data is chaotic, automation fails. When the source data is structured, automation becomes a translation exercise rather than a creative writing assignment.
Where the data actually comes from
There are two main technical architecture options for generating changelogs, and each has a different failure mode.
The first is parsing Git history directly. Tools like semantic-release read your Conventional Commits, determine the next version number, and generate a changelog automatically. This approach is lightweight and runs entirely in CI without human intervention. The tradeoff: it depends entirely on commit discipline. If engineers squash commits with vague messages, or if a single PR contains a mix of features and fixes, the output degrades immediately. It also struggles to capture the broader business context of a change. A commit that says feat(auth): add OAuth2 support is accurate but tells a support team nothing about how to explain the change to customers.
The second option is pulling from issue trackers like Jira or Linear. This approach captures intent better. A Jira ticket usually contains the product requirements and the user story, which makes for a better release note than a technical commit message. But this requires tight integration and structured ticket workflows. If engineers merge code without updating the ticket status, or if tickets are created without meaningful descriptions, the system breaks in a different way.
Mature systems combine both. They use the Git history to determine exactly what shipped, and they use the linked issue tracker metadata to explain why it shipped. A benchmark study analyzing nearly 95,000 release notes found that LLMs consistently outperform traditional baselines when they have access to structured commit tree information rather than just raw diffs. The implication is clear: the richer the upstream data, the better the automated output.
Moving humans from drafting to validating
Automated changelogs still need human review. That's not a concession. It's the design.
This doesn't mean line-by-line editing. It means validation. A technical lead or product operations manager needs to verify that the output matches what actually shipped and is intelligible to the intended audience. That review should take minutes, not hours.
Research on LLM-powered release note generation shows that systems which aggregate code, commit, and pull request details can produce release notes that outperform traditional tools on completeness, clarity, and organization. But these systems are probabilistic. They require oversight, not because the output is inherently bad, but because the output is a draft, and drafts need editorial judgment.
The goal is moving humans from drafting to validating. A technical lead reading a draft and approving it is doing editorial work. A technical lead hunting through two weeks of PRs at 11pm before a release is doing data entry. Those are not the same job, and only one of them is worth their time.
A case study at a large European bank illustrates the feedback loop: when engineers edited and approved AI-generated changelogs, the system learned from those edits and improved over time. The human review step was not overhead. It was the mechanism that made the system smarter.
Serving different readers with the same data
Different readers need different views of the same changelog.
Engineers want technical detail: which API endpoints changed, what dependencies were updated, what the migration path looks like. Support teams need customer impact summaries: how the UI changed, what workflows are affected, what questions customers will ask. Executives want business-level context: which features shipped, what customer commitments were met.
When you try to serve all audiences with a single undifferentiated list, you serve no one. Research on release note production and usage found significant discrepancies between what release note producers include and what different users actually need. Project managers care most about new features. Testers treat release notes as a source of test cases. Architects use them to track system evolution.
Mature changelog systems handle this through audience segmentation. They use tagging systems or role-based views to filter the output. A single automated pipeline might generate a detailed technical changelog for the engineering wiki, a high-level summary for the marketing newsletter, and a targeted list of bug fixes for the support team's Slack channel. The raw data is the same. The presentation is not.
Getting the output to the audience
A changelog that generates correctly but never reaches its audience is useless.
Changelog automation often fails at the last mile because teams don't plan for how the output actually gets consumed. The pipeline produces a file. The file sits in a repository. Nobody reads it.
Good distribution requires integration points: in-app notifications for end users, email digests for stakeholders, API endpoints for external tooling, Slack summaries for internal teams. The automation pipeline must push the validated changelog to the places where people already work. GitHub's release event webhooks and Slack integrations make this straightforward, but they require deliberate configuration. Distribution is not a default. It's a decision.
Anyway.
The person who used to spend hours drafting changelog entries now owns the system that produces them, ensures quality, and scales output across multiple product lines. That's the transformation. Automating a changelog is not about removing people from the process. It's about redirecting effort from repetitive drafting work into structured validation and governance. A skilled technical writer or product operations lead who understands both the audience and the source systems is essential for making automated changelogs work in practice.
Teams that generate changelogs from real engineering workflows (commits, PRs, tickets) and need a structured way to validate, manage, and distribute that output at scale will find that Doc Holiday generates directly from those workflows, and it works best when a skilled operator is running the validation and governance layer.


